Building Your First Data Pipeline: A Guide for Business Leaders
A data pipeline is an automated system that moves data from various sources, transforms it, and delivers it where your business needs it. Understanding data pipelines is crucial for business leaders because they form the foundation for reporting, analytics, and AI initiatives.

Building Your First Data Pipeline: A Non-Technical Guide for Business Leaders
A data pipeline is an automated system that moves data from various sources, transforms it into useful formats, and delivers it where your business needs it. For business leaders, understanding data pipelines is crucial because they form the foundation for everything from daily reporting to AI initiatives — without reliable data flow, your technology investments cannot deliver their promised value.
What Is a Data Pipeline?
A data pipeline is essentially a conveyor belt for information. Just as a manufacturing assembly line moves products through various stages — from raw materials to finished goods — a data pipeline moves your business information through stages of collection, cleaning, transformation, and delivery.
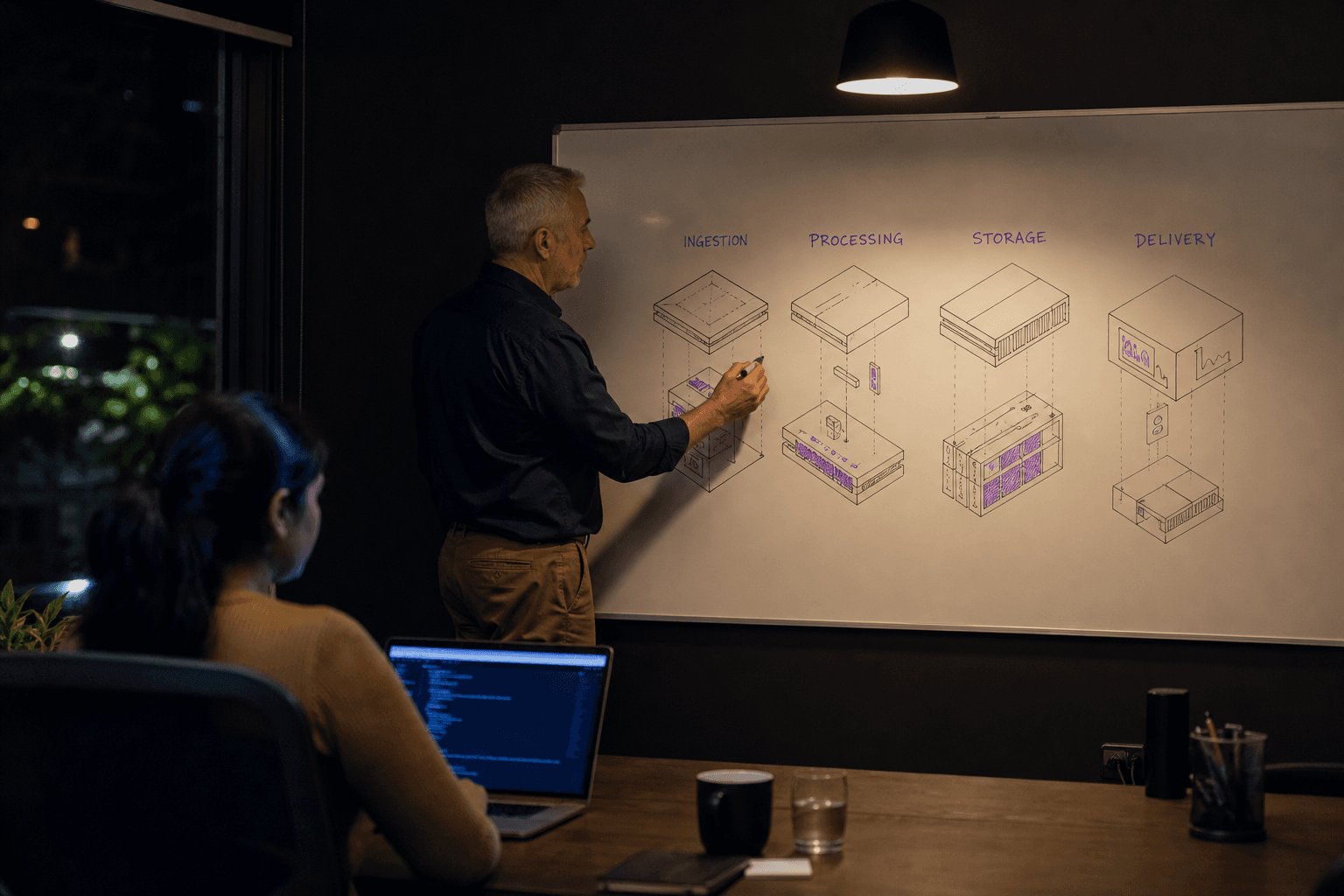
Think of it this way: your customer data lives in your CRM, sales figures sit in your e-commerce platform, and inventory levels exist in your warehouse management system. A data pipeline automatically pulls this scattered information together, ensures it's consistent and accurate, then delivers it to wherever you need it — your reporting dashboard, analytics platform, or AI applications.
The pipeline runs continuously in the background, handling new data as it arrives and keeping your downstream systems updated without manual intervention.
Why Your Business Needs a Data Pipeline
The Cost of Manual Data Handling
Without a data pipeline, your team probably spends hours each week manually downloading spreadsheets, copying data between systems, and reconciling inconsistencies. This manual process is not just time-consuming — it's error-prone and prevents your organisation from making timely decisions.
Foundation for Advanced Analytics
Data pipelines become even more critical when you want to implement AI or advanced analytics. Machine learning models require consistent, clean data to function properly. If your data is scattered across systems in different formats, AI initiatives will fail before they start.
Real-Time Decision Making
Modern businesses need to respond quickly to changing conditions. A well-designed data pipeline enables real-time or near-real-time reporting, allowing you to spot trends, identify issues, and capitalise on opportunities as they emerge.
What Good Data Pipeline Architecture Looks Like
The Four Essential Stages

| Stage | Purpose | Business Impact |
|---|---|---|
| Ingestion | Collect data from various sources | Eliminates manual data gathering |
| Processing | Clean and transform raw data | Ensures data quality and consistency |
| Storage | Store processed data efficiently | Enables fast querying and analysis |
| Delivery | Send data to end destinations | Powers dashboards, reports, and applications |
Key Architectural Principles
Reliability: The pipeline should handle failures gracefully. If one data source is temporarily unavailable, the system should continue processing other sources and retry the failed connection automatically.
Scalability: As your business grows, the pipeline should handle increasing data volumes without requiring a complete rebuild. Good architecture anticipates growth.
Monitoring: You should always know the health of your data flow. The system should alert you when something goes wrong, ideally before it affects your business operations.
Data Quality: The pipeline should include validation checks to catch and flag data quality issues before they propagate downstream.
Common Data Pipeline Patterns
Batch Processing
Batch processing handles data in scheduled chunks — perhaps processing yesterday's transactions every morning at 6 AM. This approach works well for historical reporting and analysis where real-time updates aren't critical.
Business use cases include daily sales reports, monthly financial reconciliation, and quarterly business intelligence updates.
Stream Processing
Stream processing handles data as it arrives, providing real-time or near-real-time updates. This approach is essential for operational dashboards and time-sensitive applications.
Business use cases include live inventory tracking, real-time customer behaviour analysis, and fraud detection systems.
Hybrid Approach
Many organisations use both patterns: stream processing for operational needs and batch processing for comprehensive analysis. This hybrid approach balances responsiveness with thorough data processing.
Questions to Ask Your Technical Team
Before building your first data pipeline, have these conversations with your engineering and data teams:
About Data Sources
- What data sources do we currently have?
- Which systems contain our most critical business data?
- How often does this data update?
- What format is the data in, and how clean is it?
About Requirements
- What business questions are we trying to answer?
- How quickly do we need updated information?
- Who will be consuming this data, and in what format?
- What happens if the pipeline fails — what's our backup plan?
About Implementation
- Should we build this internally or work with specialists?
- What's our budget and timeline?
- How will we monitor and maintain the pipeline?
- What skills gaps do we have in our current team?
Building vs Buying: Making the Right Choice
The decision to build your data pipeline internally or work with external specialists depends on several factors:
Build internally if you have experienced data engineers on your team, straightforward requirements, and time to iterate on the solution.
Work with specialists if you need to move quickly, have complex integration requirements, or lack internal data engineering expertise. Many mid-market companies find that partnering with experienced practitioners accelerates time-to-value significantly.
Getting Started: Your First Steps
Start Small
Begin with a simple, high-value use case rather than trying to solve everything at once. Perhaps connect your CRM and billing system to create a unified customer dashboard. Success with a smaller project builds confidence and demonstrates value.
Focus on Data Quality
Even the most sophisticated pipeline is worthless if the underlying data is poor quality. Invest time upfront in understanding your data sources and defining quality standards.
Plan for Growth
While starting small is wise, design your initial pipeline with future expansion in mind. Choose technologies and patterns that can scale as your needs grow.
Common Pitfalls to Avoid
Underestimating data complexity: Raw business data is often messier than expected. Budget time for data discovery and cleaning.
Ignoring data governance: Establish clear ownership and quality standards from the beginning. Who is responsible when something goes wrong?
Over-engineering: Don't build a system for theoretical future needs. Focus on current requirements while maintaining flexibility.
Inadequate monitoring: If you can't see when your pipeline breaks, you can't fix it quickly. Invest in proper monitoring and alerting.
The Business Impact of Good Data Infrastructure
Companies with well-designed data pipelines typically see improved decision-making speed, reduced manual effort, and better data quality across their organisation. More importantly, reliable data infrastructure becomes the foundation for AI initiatives and advanced analytics that can drive competitive advantage.
Building your first data pipeline is a significant step toward becoming a truly data-driven organisation. The investment in proper data infrastructure pays dividends not just in operational efficiency, but in enabling the advanced capabilities that modern businesses need to compete.
If you're exploring data pipeline development for your organisation, we can help. Our team specialises in building reliable data infrastructure that scales with mid-market businesses, from initial pipeline design through ongoing maintenance and expansion.
James Liu
Lead Data Engineer at Horizon Labs. Builds the data plumbing AI runs on — dbt pipelines, vector stores, feature platforms. Twelve years across Australian financial services, mining, and logistics. Believes data quality work is the highest-leverage AI investment most teams underspend on, and writes about why.


