Model Retraining: Keeping Production AI Current in Australian Business
Machine learning models degrade over time as customer behaviour shifts and market conditions evolve. This guide explores when to retrain models, how to detect performance drift, and strategies for deploying updated models safely in Australian business environments.

Model Retraining: Keeping Production AI Current in Australian Businesses
Machine learning models degrade over time. Customer behaviour shifts, market conditions evolve, and data patterns drift away from original training assumptions. For Australian mid-market companies investing in AI, maintaining model performance through systematic retraining is crucial for sustained business value.
A retail recommendation system trained on pre-COVID shopping patterns would struggle with today's omnichannel customer behaviour. Similarly, a fraud detection model built on 2022 transaction data might miss emerging attack vectors targeting Australian payment systems in 2024.
This article examines when to retrain models, how to detect performance drift, and strategies for deploying updated models safely in production environments.
When Models Need Retraining
Model retraining becomes necessary when performance degrades due to changes in underlying data patterns or business conditions. Australian businesses typically encounter three primary triggers: data drift, concept drift, and measurable performance decay.

Data drift occurs when statistical properties of input features change over time. For example, an Australian fintech's credit scoring model might experience drift as interest rates shift borrowing patterns, or as new demographic segments enter the market.
Concept drift happens when relationships between inputs and outputs change. A logistics optimisation model trained during stable fuel prices might become less accurate as volatile energy costs alter the relationship between delivery routes and operational costs.
Performance decay manifests through declining business metrics even when statistical measures appear stable. A customer churn model might maintain good precision and recall while failing to identify high-value customers most likely to leave.
Successful retraining strategies focus on business impact rather than purely statistical measures. Model accuracy means little if customer satisfaction or revenue outcomes deteriorate.
Triggered vs Scheduled Retraining Approaches
Production retraining strategies typically combine event-driven responses with regular update cycles. This hybrid approach balances computational efficiency with responsiveness to critical changes.
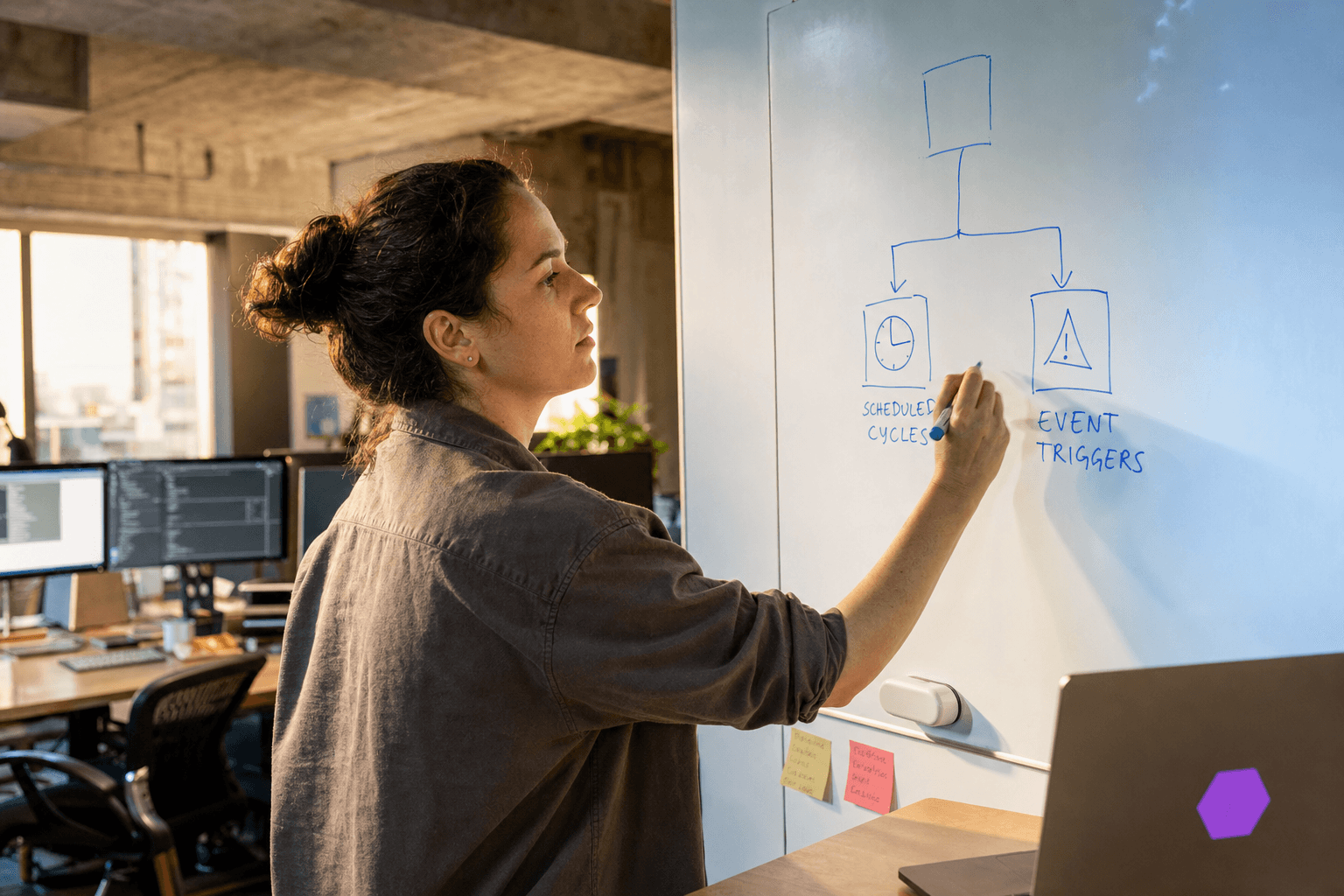
Triggered retraining responds to specific conditions: performance thresholds breached, significant drift detected, or major business events. This approach conserves resources and ensures timely responses but requires robust monitoring infrastructure and clearly defined trigger conditions.
Scheduled retraining follows predetermined intervals—monthly, quarterly, or seasonal cycles that align with business rhythms. Australian retailers might schedule retraining around major shopping periods like Christmas or EOFY sales, while financial services companies might align with regulatory reporting cycles.
A manufacturing company might implement weekly scheduled retraining for demand forecasting models while maintaining triggered retraining for quality control systems that must respond immediately to process changes.
The optimal frequency depends on data velocity, business criticality, and available computational resources. High-stakes applications like fraud detection warrant more frequent updates than recommendation systems.
Data Drift Detection in Production
Early detection of data drift prevents model degradation before business impact occurs. Effective monitoring combines statistical methods with domain expertise to catch different types of distributional changes.
Statistical monitoring compares current data distributions with training data baselines. The Kolmogorov-Smirnov test works well for continuous variables, while chi-square tests suit categorical features. Population Stability Index (PSI) provides a single metric for tracking feature stability over time.
Business metric monitoring often detects meaningful drift before statistical tests trigger. An e-commerce platform might monitor conversion rates by traffic source, while a logistics company tracks delivery success rates across different regions.
Domain-specific indicators leverage business knowledge to identify drift drivers. Australian seasonal patterns, regulatory changes, or economic shifts might predict model degradation before data analysis confirms it.
Implement drift detection as continuous monitoring rather than batch processing. Real-time detection enables faster response to critical changes that could impact customer experience or business outcomes.
For Australian mid-market companies, focus monitoring efforts on the most business-critical features rather than attempting comprehensive coverage of all model inputs.
Safe Model Deployment Through Testing
Deploying retrained models without proper validation risks degrading production performance despite improved offline metrics. Systematic testing approaches reduce deployment risks while providing empirical evidence of model improvements.
Shadow deployment runs new models alongside production systems without affecting user experience. This approach works particularly well for delayed-feedback applications like fraud detection, where you can compare predictions against eventual outcomes without impacting operations.
Champion-challenger frameworks gradually shift traffic from existing models to new versions based on performance criteria. Industry practice suggests starting with a small percentage of traffic—typically 5-10%—while monitoring key business metrics before increasing allocation.
Canary releases deploy new models to specific user segments or geographic regions before broader rollout. An Australian retailer might test updated recommendation models in one state before national deployment.
Define success criteria before testing begins. Statistical significance alone doesn't guarantee business value. A model with slightly better accuracy might deliver worse user experience if it increases response time or generates less relevant recommendations.
For Australian businesses, consider regulatory compliance during testing phases. Financial services and healthcare applications may require additional validation steps or documentation before deployment.
Risk Mitigation and Rollback Strategies
Effective rollback capabilities enable rapid recovery when new models underperform in production. Preparation and automated monitoring are essential for minimising business impact.
Automated rollback triggers monitor key performance indicators and revert to previous model versions when thresholds are breached. Business metrics like conversion rates, customer satisfaction scores, or transaction success rates often provide more actionable signals than statistical measures.
Circuit breaker patterns temporarily disable problematic models when error rates spike, falling back to simpler rule-based systems or human decision-making processes while issues are resolved.
Version management maintains multiple model versions simultaneously, enabling quick switches between different implementations. This approach requires careful infrastructure planning but provides maximum flexibility during deployment issues.
Gradual rollback reduces traffic to underperforming models incrementally rather than immediate full reversion. This approach helps isolate whether poor performance affects all users or specific segments.
Document rollback procedures and practice execution during low-risk periods. When production incidents occur, clear procedures and practised responses minimise downtime and business impact.
Infrastructure for Automated Retraining
Automated retraining requires robust infrastructure that handles data pipeline management, model training orchestration, and deployment automation. Australian mid-market companies benefit from cloud-native solutions that provide scalability without large upfront infrastructure investments.
Data pipeline orchestration ensures training data remains current and consistent. Modern workflow orchestration tools can handle complex dependencies between data sources, feature engineering steps, and model training processes.
Model versioning and registry systems track model lineage, performance metrics, and deployment status. This capability proves essential for regulatory compliance and audit requirements common in Australian financial services and healthcare.
Automated testing pipelines validate new models against historical data, run statistical tests, and verify performance criteria before deployment consideration.
Monitoring and alerting infrastructure tracks model performance, data quality, and business metrics continuously. Early warning systems enable proactive intervention before performance degradation impacts customers.
For companies without dedicated MLOps teams, managed solutions or consulting partnerships can provide automated retraining capabilities without requiring extensive internal infrastructure development.
Performance Monitoring and Business Alignment
Successful automated retraining aligns technical model performance with business outcomes. Monitoring strategies should emphasise metrics that directly relate to customer experience and revenue impact.
Business-first metrics prioritise measures that matter to stakeholders over purely technical performance indicators. Customer satisfaction, revenue per user, or operational efficiency metrics often provide more actionable insights than statistical measures like F1-scores.
Leading vs lagging indicators balance immediate feedback with longer-term trend analysis. Conversion rate changes might indicate model issues immediately, while customer lifetime value impacts take months to materialise.
Segment-specific monitoring tracks performance across different customer groups, geographic regions, or product categories. Model performance might vary significantly across segments even when aggregate metrics appear stable.
Comparative analysis evaluates new models against business baselines rather than just previous model versions. Sometimes reverting to simple rules or human decision-making outperforms complex ML approaches.
Regular business review cycles ensure retraining strategies remain aligned with evolving company priorities and market conditions.
Implementation Roadmap for Australian Companies
Implementing automated model retraining requires careful planning and phased rollout. Start with highest-impact, lowest-risk applications before expanding to more complex scenarios.
Phase 1: Foundation establishes monitoring infrastructure and manual retraining processes. Focus on one critical model with clear business metrics and straightforward data pipelines.
Phase 2: Automation introduces triggered retraining for the initial model, implementing basic drift detection and automated deployment pipelines.
Phase 3: Expansion extends automated retraining to additional models, incorporating more sophisticated drift detection and testing frameworks.
Phase 4: Optimisation implements advanced techniques like multi-armed bandit testing, sophisticated rollback strategies, and business-optimised retraining schedules.
Each phase should demonstrate clear business value before proceeding. Rushing implementation without proper foundation often leads to unreliable systems that require expensive remediation.
Getting Started with Model Retraining
For Australian mid-market companies beginning their automated retraining journey, start with systematic assessment of existing models and infrastructure capabilities.
Identify models with the highest business impact and most observable performance metrics. Customer-facing applications like recommendation systems or pricing optimisation often provide clear feedback signals and measurable business outcomes.
Establish baseline monitoring for these high-impact models before implementing automated retraining. Understanding current performance patterns and drift characteristics informs effective retraining strategies.
Consider the full lifecycle cost of automated retraining, including infrastructure, monitoring, and operational overhead. Sometimes manual retraining schedules provide better cost-effectiveness for models with predictable drift patterns.
Building effective automated retraining capabilities requires combining technical expertise with deep understanding of business requirements and operational constraints. For many Australian companies, partnering with experienced practitioners accelerates implementation while avoiding common pitfalls.
Our AI engineering and AI operations services help companies implement robust model retraining strategies that maintain AI performance while supporting business growth. Get in touch to discuss your model maintenance challenges and explore solutions that fit your technical environment and business requirements.
Chris Kerr
Partner at Horizon Labs, an AI product consultancy and venture studio. A commercially focused product and technology leader with 20+ years building and scaling digital platforms, teams, and businesses across SaaS, travel, eCommerce, logistics and transport, and digital marketing — operating at the intersection of product, engineering, and data. Writes about platform strategy, AI transformation, modern data ecosystems, and the operational discipline that separates AI demos from AI products.


