AWS SageMaker vs Self-Hosted GPU Serving: Cost and Control
AWS SageMaker and self-hosted GPU serving on A100 or H100 hardware each make sense under different conditions — and the wrong choice becomes expensive quickly. This article breaks down the cost structure, operational trade-offs, and decision framework for Australian engineering teams moving ML models to production.

When your machine learning models need to move from notebook to production, one of the earliest and most consequential decisions is where they run. AWS SageMaker is the default choice for many Australian engineering teams — it is managed, familiar, and fast to get started. But as models grow larger and inference volumes increase, self-hosted GPU serving on A100 or H100 hardware starts to look attractive. The right answer depends on your stage, your team, and what you are actually optimising for.
What Is AWS SageMaker?
AWS SageMaker is a fully managed machine learning platform that handles model training, deployment, and monitoring inside the AWS ecosystem. It abstracts away the infrastructure layer — you do not provision GPU instances, manage container orchestration, or maintain serving frameworks directly. You define endpoints, and AWS handles the rest, including autoscaling, health checks, and integration with other AWS services.

SageMaker is not a single product. It is a suite of tools covering data labelling, experiment tracking, training jobs, real-time inference endpoints, batch transform, feature stores, and model monitoring. The breadth is both its strength and its source of complexity.
What Does Self-Hosted GPU Serving Look Like?
Self-hosted GPU serving means running your inference workloads on GPU hardware you provision and manage yourself — either on bare metal in a colocation facility, on cloud instances where you control the operating system and stack, or on-premises. Popular frameworks for this include NVIDIA Triton Inference Server, vLLM for large language models, and Ray Serve for distributed inference.
The A100 and H100 are NVIDIA's current generation data centre GPUs. H100s in particular are optimised for transformer-based model architectures and offer substantially higher throughput for large language model inference than previous generations. However, securing H100 capacity — whether on-demand cloud or bare metal — has been constrained globally, a dynamic that affects Australian teams accessing these resources through local cloud regions.
SageMaker Costs: What You Are Actually Paying For
SageMaker pricing has two distinct layers. The first is the underlying compute: you pay for the GPU or CPU instance your endpoint runs on, billed per second of uptime. The second is the SageMaker service markup on top of that compute, which varies by feature. Real-time inference endpoints, for instance, carry a per-instance cost that is higher than running the equivalent raw EC2 instance yourself.
For teams running endpoints with steady, predictable traffic, this markup can become meaningful at scale. For teams with spiky or unpredictable traffic, SageMaker's serverless inference and managed autoscaling can offset that overhead by avoiding idle compute costs.
The real cost of SageMaker, however, is not just the line item — it is the cost of not having to manage infrastructure. If your team does not have deep MLOps experience, the time and reliability cost of building equivalent infrastructure yourself often exceeds the platform premium.
Self-Hosted GPU Costs: What You Are Actually Paying For
Self-hosted GPU serving shifts cost from platform fees to engineering and operations labour. The compute itself — particularly A100 instances on AWS, Azure, or GCP, or bare metal through providers like CoreWeave or Lambda Labs — can be materially cheaper per GPU-hour than equivalent SageMaker endpoints when you run at high utilisation.
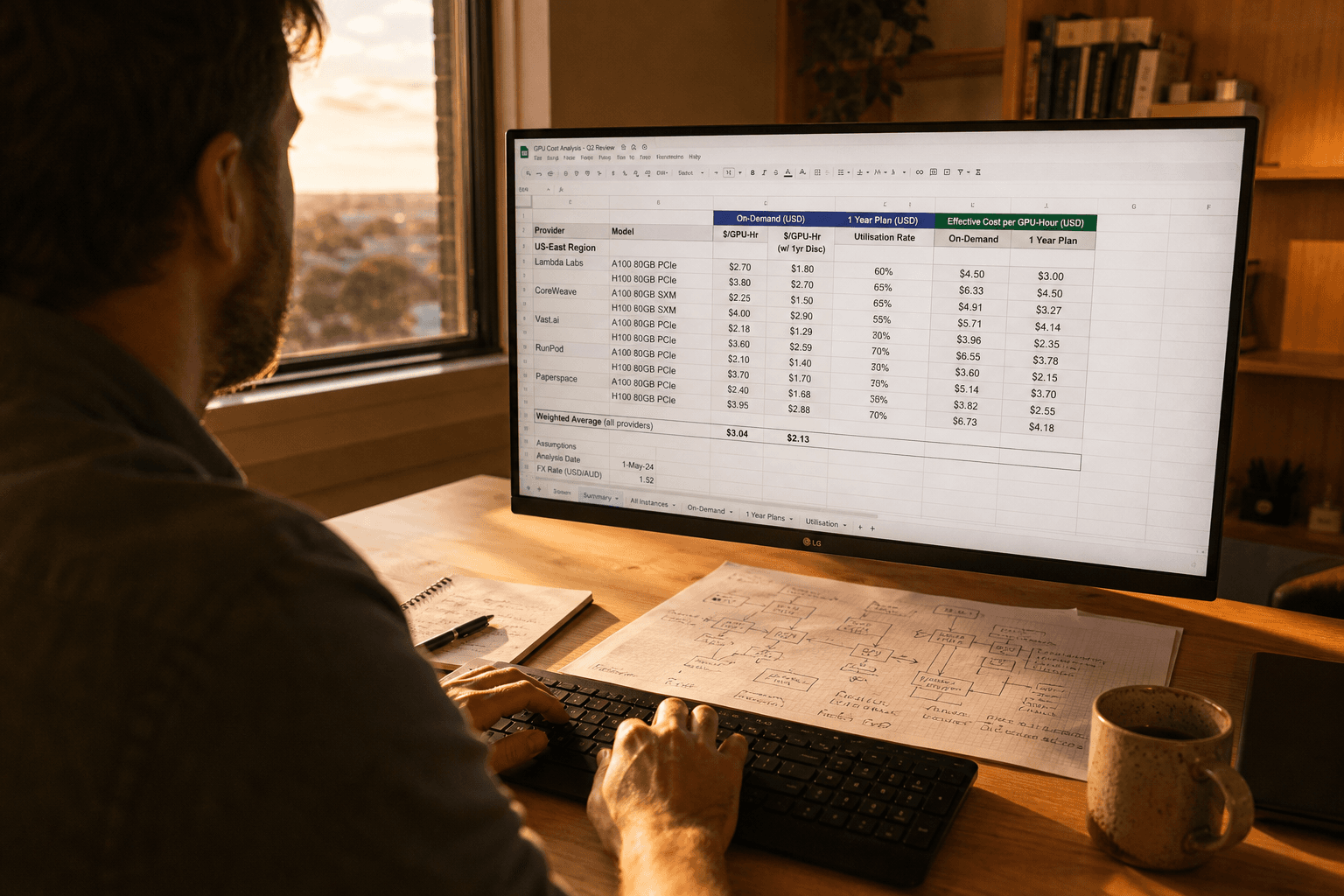
The trade-off is that high utilisation is hard to guarantee. GPUs sitting idle at 30% utilisation because you have not optimised batching, quantisation, or request routing are expensive. The economics of self-hosting favour teams that can run GPUs at sustained high utilisation and have the engineering capacity to continuously optimise the serving stack.
Beyond compute, self-hosted serving requires investment in: container orchestration (typically Kubernetes), autoscaling logic, load balancing, model versioning and rollout tooling, observability and alerting, and security hardening. These are not trivial engineering problems, and they compound over time.
Operational Burden: A Realistic Comparison
| Dimension | AWS SageMaker | Self-Hosted GPU Serving |
|---|---|---|
| Infrastructure provisioning | Managed | Team responsibility |
| Autoscaling | Built-in | Custom (Kubernetes HPA, KEDA, etc.) |
| Model monitoring & drift detection | Built-in (Model Monitor) | Custom or third-party tooling |
| Security patching | AWS responsibility | Team responsibility |
| Multi-model serving | Supported natively | Custom orchestration required |
| Serving framework flexibility | Limited to supported containers | Full flexibility |
| Cold start latency | Present on serverless endpoints | Configurable |
| Observability | CloudWatch integrated | Custom stack required |
Neither column is inherently better. The table reflects trade-offs in control versus responsibility. SageMaker abstracts operational complexity at the cost of flexibility. Self-hosted serving gives you full control at the cost of operational ownership.
When Does SageMaker Win?
SageMaker is the stronger choice in several common scenarios for Australian mid-market companies.
When your team is small or ML-new. If you have fewer than two or three engineers who can own the serving infrastructure, SageMaker's managed layer protects you from operational incidents caused by infrastructure you do not fully understand. The platform overhead is a reasonable price for reliability.
When you are already deep in AWS. SageMaker integrates natively with S3, IAM, CloudWatch, VPC, and the rest of the AWS ecosystem. If your data pipelines, feature stores, and application infrastructure all live in AWS, the integration cost of moving to self-hosted serving is real and often underestimated.
When your models are standard sizes. For models in the sub-7B parameter range, or for classical ML workloads, SageMaker endpoints are well-optimised and the per-instance overhead is proportionally smaller. The push toward self-hosted serving is most compelling for very large models where GPU efficiency directly drives cost at scale.
When compliance and auditability matter. SageMaker's managed logging, IAM integration, and audit trails are valuable for Australian organisations operating under APRA CPS 234, privacy obligations under the Australian Privacy Act, or sector-specific regulatory requirements. Replicating equivalent auditability on self-hosted infrastructure takes deliberate engineering effort.
When Does Self-Hosted GPU Serving Win?
Self-hosted serving becomes genuinely compelling under specific conditions.
When you are serving large language models at scale. For LLM inference — particularly models above 13B parameters — the economics of managed endpoints can become difficult to justify. Frameworks like vLLM provide continuous batching, KV cache management, and tensor parallelism that dramatically improve GPU utilisation. These optimisations are not always available or configurable through managed endpoint abstractions.
When you need hardware flexibility. SageMaker's instance selection is constrained by what AWS makes available in your region. Teams needing H100s with NVLink, or specific memory configurations for model sharding, may find the managed platform limiting. Self-hosted or bare metal gives you access to hardware configurations that managed platforms do not expose.
When you have the MLOps capability to own it. Self-hosting is not a cost-saving measure for teams that lack MLOps depth — it is a cost-shifting measure that trades platform fees for engineering labour. Teams with dedicated ML platform engineers, Kubernetes expertise, and robust observability practices can run self-hosted serving stacks efficiently and maintain the reliability needed for production workloads.
When multicloud or vendor independence is a strategic requirement. Some Australian organisations — particularly those with data sovereignty requirements or negotiating leverage with cloud providers — have strategic reasons to avoid deep platform lock-in. Self-hosted serving on abstracted infrastructure supports a more portable deployment model.
The Hidden Variable: Cold Start and Latency Requirements
Latency requirements often determine feasibility before cost enters the conversation. SageMaker's real-time endpoints can be configured to keep instances warm, but serverless endpoints have cold start latency that makes them unsuitable for synchronous, user-facing inference. Self-hosted serving on pre-warmed GPU instances eliminates this, but at the cost of paying for idle capacity.
For batch or asynchronous inference — document processing, overnight enrichment, background classification — the cold start issue largely disappears, and SageMaker's batch transform or asynchronous endpoints become very cost-effective. The architecture of your application and the latency SLA of your inference path should drive serving infrastructure decisions as much as raw cost.
What This Means for Your MLOps Architecture
The SageMaker versus self-hosted decision is rarely permanent. Most mature ML platforms evolve through a recognisable pattern: start managed for speed, reach a scale threshold where the economics shift, then selectively move high-volume workloads to optimised self-hosted infrastructure while keeping lower-volume or experimental workloads on managed platforms.
This hybrid approach is pragmatic but requires clear MLOps governance: consistent model packaging, portable monitoring, and infrastructure-agnostic deployment pipelines. Building that foundation early — even when you are on SageMaker — reduces the migration cost when you eventually need to move.
If you are thinking about how your AI engineering stack should be structured, the serving infrastructure decision is inseparable from your model lifecycle, data infrastructure, and team capability maturity. We have written more about how to get the foundations right in our post on data infrastructure: building the foundation for AI.
A Framework for Making the Decision
Rather than treating this as a binary choice, evaluate it across four dimensions:
-
Team MLOps maturity — Can your team own the operational burden of self-hosted serving, including on-call, incident response, and continuous optimisation? If not, the managed overhead is justified.
-
Inference volume and utilisation — At what GPU utilisation does your self-hosted serving stack need to run to break even on the platform premium? Model this honestly before committing.
-
Model size and framework requirements — Standard models on standard frameworks fit managed platforms well. Large models with specific framework requirements often do not.
-
Regulatory and data sovereignty requirements — Australian organisations in regulated sectors should evaluate whether managed platform data handling aligns with their compliance obligations under Australian law before assuming SageMaker is the simpler choice.
If you are working through your AI product strategy and this decision is on the critical path, it is worth getting the architecture right before you build serving infrastructure you will need to replace in twelve months.
Production ML infrastructure is genuinely hard, and the serving layer is where underinvestment shows up as reliability incidents and unexpected costs. If you are evaluating your ML serving architecture — whether you are on SageMaker today or considering a move to self-hosted GPU infrastructure — we are happy to work through the specifics with you. The right answer depends on your stack, your team, and your growth trajectory, and we would rather help you model it accurately than give you a default recommendation.
Chris Kerr
Partner at Horizon Labs, an AI product consultancy and venture studio. A commercially focused product and technology leader with 20+ years building and scaling digital platforms, teams, and businesses across SaaS, travel, eCommerce, logistics and transport, and digital marketing — operating at the intersection of product, engineering, and data. Writes about platform strategy, AI transformation, modern data ecosystems, and the operational discipline that separates AI demos from AI products.


