Predictive Maintenance with Machine Learning: Implementation Guide
Learn how to implement predictive maintenance with machine learning, from sensor data pipelines to model deployment. Includes a detailed case study showing 84% downtime reduction in Australian mining operations.

Predictive Maintenance with Machine Learning: A Practical Implementation Guide
Predictive maintenance transforms how manufacturers prevent equipment failures by using machine learning to predict when machines need attention before they break down. Unlike reactive maintenance (fix after failure) or preventive maintenance (scheduled intervals), predictive maintenance uses real-time sensor data and ML models to identify the optimal maintenance window — reducing downtime, cutting costs, and extending equipment life.
This practical guide walks through implementing predictive maintenance with machine learning, from sensor data collection through model deployment and monitoring. We'll cover the technical architecture, explore real-world challenges, and examine a case study where predictive maintenance delivered 84% downtime reduction for an Australian manufacturing operation.
Understanding Predictive Maintenance with Machine Learning
Predictive maintenance with machine learning uses algorithms to analyse equipment sensor data and predict when maintenance should occur. The system monitors vibration, temperature, pressure, electrical current, and other operational parameters to detect patterns that indicate impending failure.
Machine learning predictive maintenance differs from traditional condition monitoring by learning from historical patterns rather than relying solely on threshold-based alerts. Where traditional systems might trigger an alert when vibration exceeds 10mm/s, ML models can detect subtle combinations of temperature rise, frequency changes, and load variations that indicate bearing wear 2-3 weeks before failure.
The Australian manufacturing sector faces unique challenges for predictive maintenance implementation. According to the Australian Industry Group's 2023 Manufacturing Survey, unplanned downtime costs Australian manufacturers an average of $50,000 per hour. Remote locations, skilled technician shortages, and aging infrastructure make predictive maintenance particularly valuable for Australian operations.
Sensor Data Pipeline Architecture
Building a robust sensor data pipeline forms the foundation of any predictive maintenance system. The pipeline must collect, process, and store high-frequency sensor data while handling network interruptions and edge computing constraints common in industrial environments.
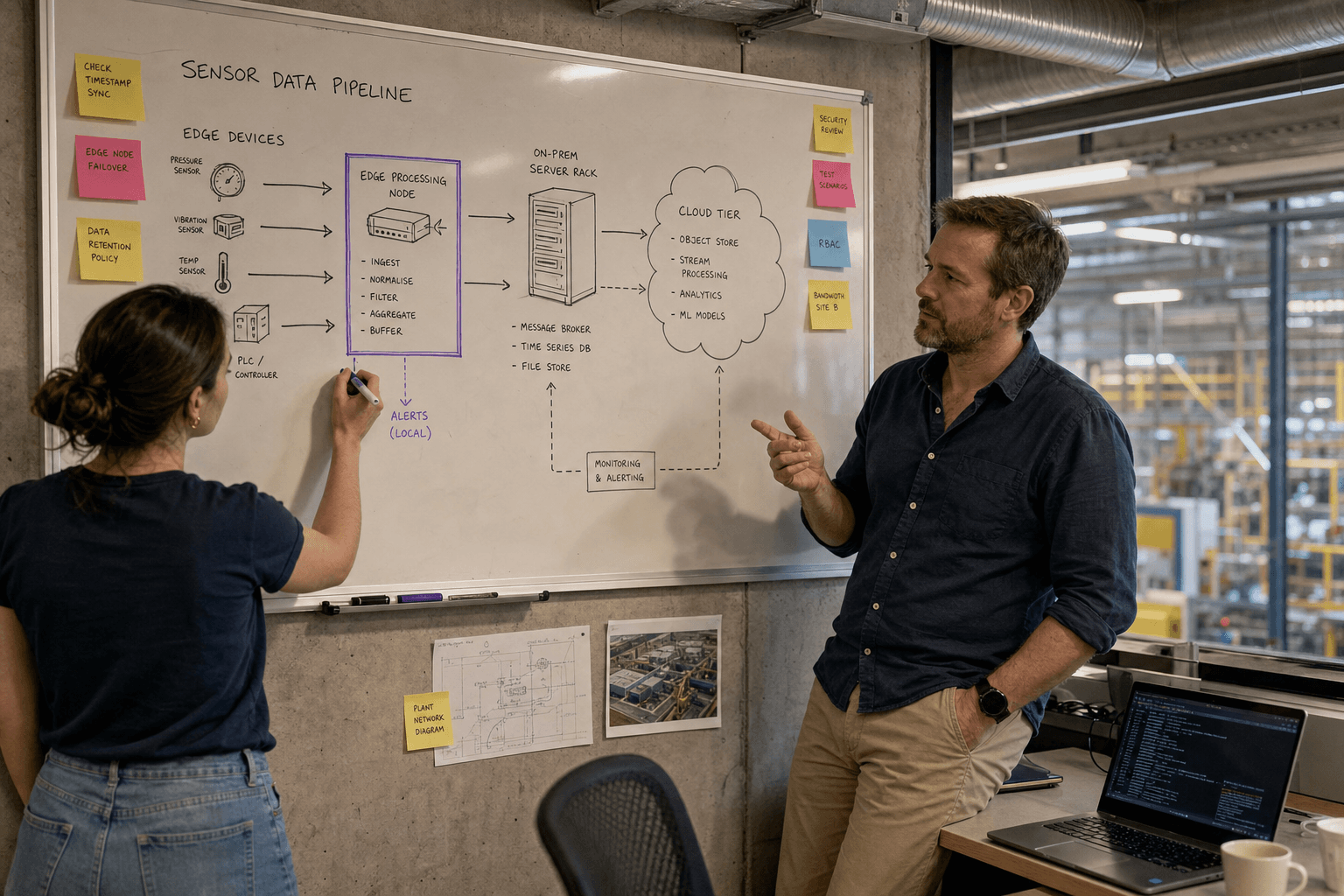
Data Collection Strategy
Effective sensor data collection requires careful consideration of sampling rates, sensor placement, and data quality. Vibration sensors typically require 10-50 kHz sampling rates to capture bearing defect frequencies, while temperature sensors can operate at 1Hz intervals. Current sensors on motor-driven equipment should sample at least 1kHz to detect electrical anomalies.
Sensor placement strategy depends on equipment criticality and failure modes. For rotating equipment, accelerometers should be mounted on bearing housings in both horizontal and vertical orientations. Temperature sensors belong near heat sources like bearings, motors, and hydraulic components. Current transformers monitor electrical signatures that reveal motor inefficiencies and load variations.
Data quality validation happens at the edge before transmission to prevent corrupted data from contaminating ML models. Implement range checking (temperature sensors reading -40°C in Queensland indicate sensor failure), signal validation (accelerometer readings with impossible acceleration levels), and timestamp verification to ensure data integrity.
Edge vs Cloud Processing
The edge vs cloud decision significantly impacts system performance, costs, and reliability. Edge processing reduces latency, handles network interruptions, and keeps sensitive data on-site — critical for mining operations in remote Western Australia or manufacturing plants with strict data governance requirements.
| Approach | Latency | Cost | Reliability | Use Case |
|---|---|---|---|---|
| Edge | <100ms | High initial | Network independent | Critical safety systems |
| Cloud | 500-2000ms | Low initial | Network dependent | Historical analysis |
| Hybrid | <500ms | Medium | Fault tolerant | Production optimization |
Edge deployment typically uses industrial PCs or ruggedised gateways running containerised ML models. Popular choices include Dell Edge Gateways, HPE Edgeline systems, or custom solutions built on NVIDIA Jetson platforms for GPU-accelerated inference.
Cloud deployment offers unlimited compute resources and easier model updates but requires reliable connectivity. Australian manufacturers often implement hybrid architectures: edge devices handle real-time anomaly detection while cloud systems perform complex pattern analysis and model training.
Feature Engineering for Industrial Equipment
Feature engineering transforms raw sensor data into meaningful inputs for machine learning models. Industrial equipment generates thousands of data points per second, but effective predictive maintenance models typically use 50-200 carefully engineered features that capture equipment behaviour patterns.
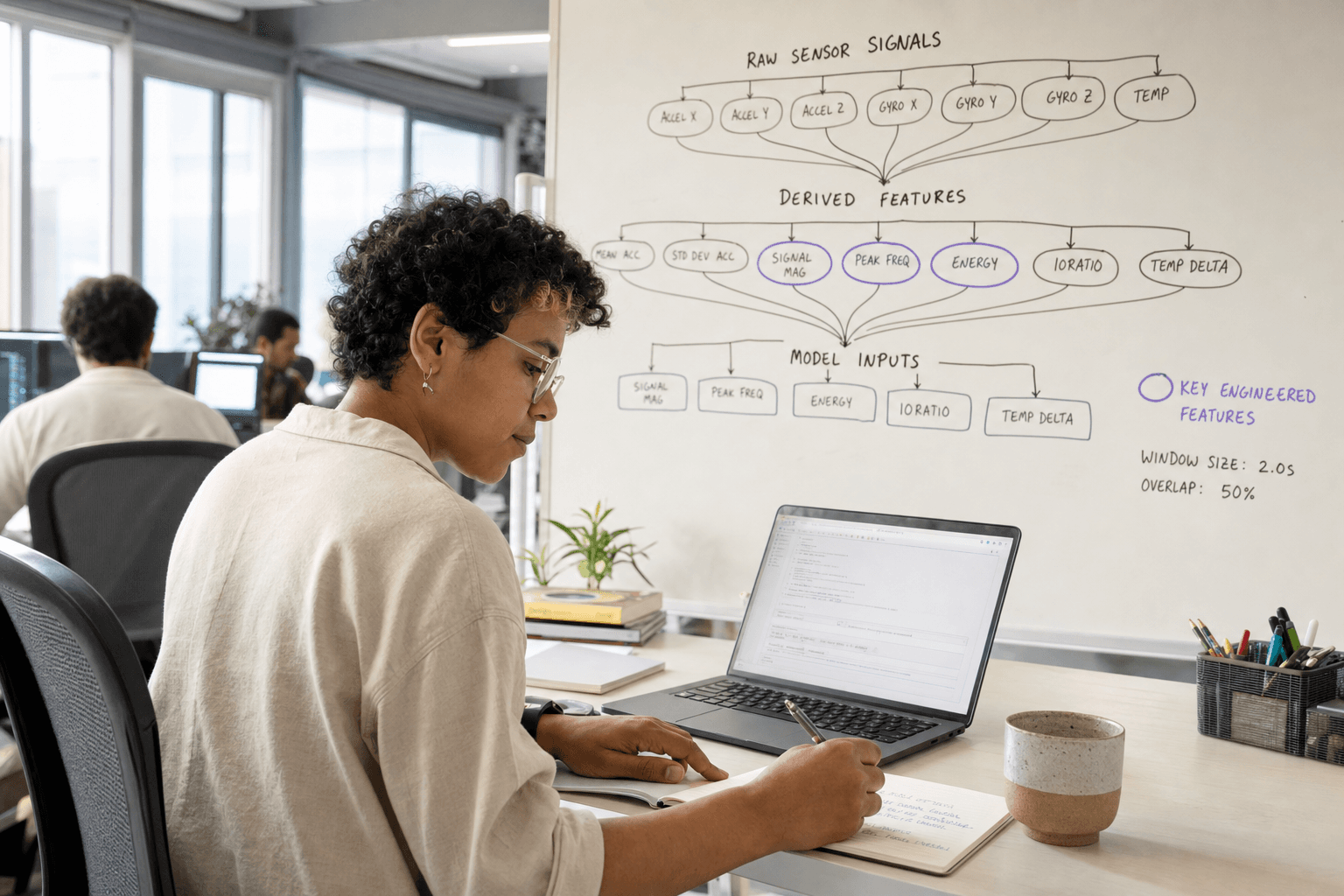
Time-Domain Features
Time-domain features capture statistical properties of sensor signals over time windows. Root Mean Square (RMS) values indicate overall vibration energy and correlate strongly with bearing condition. Peak values identify impact events from worn gears or loose components. Crest factor (peak/RMS ratio) reveals bearing defects before RMS values change significantly.
Kurtosis measures signal peakiness and increases dramatically when rolling element bearings develop spalls or cracks. Skewness indicates signal asymmetry, useful for detecting shaft misalignment or belt tension issues. Standard deviation provides a stable measure of signal variability that remains consistent across different operating conditions.
Frequency-Domain Features
Frequency analysis reveals equipment-specific failure signatures invisible in time-domain data. Fast Fourier Transform (FFT) analysis identifies bearing defect frequencies, gear mesh frequencies, and motor electrical faults. Envelope analysis extracts bearing fault signatures from high-frequency resonances excited by defects.
Spectral features include band power (energy in specific frequency ranges), spectral centroid (frequency "centre of mass"), and harmonic distortion ratios. These features remain stable during normal operation but change predictably as equipment degrades.
For rotating equipment, envelope detection followed by FFT analysis (envelope spectrum) provides the most reliable bearing fault detection. This technique filters high-frequency content, applies envelope detection, then performs FFT to reveal bearing defect frequencies typically buried in noise.
Operational Context Features
Machine learning models must account for normal operational variations to avoid false alarms. Load conditions, ambient temperature, production rates, and maintenance history significantly influence sensor readings. A motor drawing 80% rated current generates different vibration patterns than one at 40% load.
Operational context features include equipment runtime hours, production throughput, ambient temperature compensation, and maintenance event timestamps. These features help models distinguish between normal operational changes and actual equipment degradation.
Model Selection: Time Series vs Classification Approaches
Choosing between time series and classification approaches depends on available data, prediction timeline, and operational requirements. Each approach offers distinct advantages for different predictive maintenance scenarios.
Time Series Models
Time series models predict when equipment parameters will exceed failure thresholds, providing specific timeframes for maintenance scheduling. Long Short-Term Memory (LSTM) networks excel at learning long-term dependencies in sensor data, while ARIMA models work well for stationary signals with clear trends.
LSTM networks handle multivariate time series data effectively, learning relationships between temperature, vibration, and current measurements. These models predict equipment health scores or remaining useful life (RUL) estimates, enabling precise maintenance scheduling.
ARIMA models suit applications with clear seasonal patterns or trend components. Pump performance degradation often follows predictable patterns that ARIMA models capture effectively. However, ARIMA assumes stationarity and may struggle with sudden equipment changes.
Classification Models
Classification models predict equipment health states (healthy, warning, critical) rather than specific failure times. Random Forest classifiers handle mixed data types well and provide feature importance rankings that help maintenance teams understand key failure indicators.
Gradient Boosting (XGBoost, LightGBM) often outperforms other algorithms for industrial datasets with mixed sensor types and operational variables. These models excel at capturing non-linear relationships between features and handle missing data gracefully.
Support Vector Machines work well for binary classification (normal vs abnormal) with small datasets but scale poorly to large sensor datasets. Neural networks provide high accuracy but require significant training data and computational resources.
Real-World Implementation: Australian Mining Case Study
A major Australian iron ore mining operation implemented predictive maintenance across their conveyor system, achieving 84% downtime reduction within 18 months. This case study illustrates practical implementation challenges and solutions for large-scale industrial deployments.
The Challenge
The mining operation ran 40+ conveyor systems across a 60km transport network in remote Western Australia. Unplanned conveyor failures caused cascading shutdowns affecting the entire production chain. Traditional maintenance relied on fixed schedules and reactive repairs, resulting in 15-20 hours monthly downtime per conveyor.
Harsh environmental conditions — temperatures exceeding 45°C, dust, humidity, and limited network connectivity — complicated sensor deployment. The nearest major city was 800km away, making emergency repairs expensive and time-consuming.
Technical Implementation
Sensor Strategy: Engineers installed accelerometers on roller bearings, current transformers on drive motors, and thermal cameras monitoring belt temperature. Each conveyor system included 15-25 sensors depending on length and complexity.
Edge Computing Architecture: Ruggedised industrial PCs at each conveyor collected sensor data and ran real-time anomaly detection models. These edge devices stored 30 days of raw data and transmitted feature summaries and alerts via satellite connectivity.
Feature Engineering Pipeline: The system calculated 180 features per conveyor including statistical measures (RMS, kurtosis, peak values), frequency domain features (envelope spectrum analysis, harmonic ratios), and operational context (belt speed, ambient temperature, production tonnage).
Model Architecture: A hybrid approach combined classification for real-time alerts with time series models for maintenance scheduling. XGBoost classifiers provided 4-hour ahead failure warnings while LSTM networks predicted remaining useful life for maintenance planning.
Results and Lessons Learned
The implementation delivered exceptional results:
- 84% reduction in unplanned downtime (from 18 hours to 3 hours monthly average)
- $2.3M annual savings from reduced emergency repairs and production losses
- 40% reduction in maintenance costs through optimised part inventory and scheduling
- 95% alert accuracy after 12 months of model tuning
Key Success Factors:
- Gradual rollout: Started with two critical conveyors before expanding system-wide
- Maintenance team engagement: Involved experienced technicians in feature selection and alert validation
- Robust edge computing: Local processing handled network interruptions without data loss
- Continuous model improvement: Monthly retraining with new failure examples improved accuracy
Challenges Overcome:
- False alarms: Initial deployment generated 40% false positive rate, reduced through better feature engineering and operational context inclusion
- Environmental durability: Dust and temperature extremes required IP65-rated enclosures and thermal management
- Change management: Maintenance teams initially resisted ML recommendations, requiring gradual trust-building through demonstrated accuracy
Model Deployment and Monitoring
Successful predictive maintenance deployment requires robust model serving infrastructure and continuous monitoring to maintain performance as equipment and operating conditions change.
Deployment Architecture
Production deployment typically uses containerised models deployed via Kubernetes for scalability and reliability. Docker containers package ML models with their dependencies, ensuring consistent behaviour across development and production environments.
Model serving frameworks like MLflow, Seldon Core, or cloud-native solutions (AWS SageMaker, Azure ML) provide REST API endpoints for real-time predictions. These platforms handle model versioning, A/B testing, and rollback capabilities essential for production systems.
For edge deployment, lightweight frameworks like TensorFlow Lite, ONNX Runtime, or Intel OpenVINO optimise models for resource-constrained devices. Model quantisation reduces memory usage while maintaining accuracy, crucial for industrial PCs with limited RAM.
Monitoring and Alerting
Model performance monitoring tracks prediction accuracy, data drift, and system health. Data drift detection compares incoming sensor data distributions against training data to identify when models need retraining.
Business metrics monitoring ensures ML predictions translate to operational value. Track alert response times, maintenance scheduling efficiency, and false alarm rates alongside technical metrics like prediction latency and model accuracy.
Alert fatigue prevention requires careful threshold tuning and alert prioritisation. Implement severity levels (informational, warning, critical) with different notification channels. Critical alerts trigger immediate SMS/phone notifications while informational alerts appear in dashboards.
Model Retraining Strategy
Predictive maintenance models degrade over time as equipment ages, operating conditions change, or new failure modes emerge. Implement automated retraining pipelines triggered by performance degradation or data drift detection.
Scheduled retraining (monthly or quarterly) incorporates new failure examples and operational data. Triggered retraining responds to significant performance drops or operational changes. Continuous learning systems update models incrementally but require careful validation to prevent model corruption.
A/B testing compares new model versions against existing models using real operational data. Deploy new models to subset of equipment first, monitoring performance before full rollout.
Implementation Roadmap and ROI Considerations
Implementing predictive maintenance requires systematic planning, realistic timeline expectations, and clear ROI metrics. Australian manufacturers typically see positive ROI within 12-18 months for critical equipment implementations.
Phase 1: Pilot Implementation (Months 1-6)
Start with 2-3 critical pieces of equipment with clear failure modes and high downtime costs. Install sensors, implement basic data collection, and develop initial models using historical failure data.
Success metrics include sensor data quality, initial model accuracy (target >80%), and maintenance team acceptance. Focus on proving technical feasibility and building organisational confidence.
Phase 2: Production Scaling (Months 7-12)
Expand to 10-15 equipment pieces, implement automated alerting, and integrate with maintenance management systems (SAP PM, Maximo, eMaint). Develop standard deployment procedures and train maintenance teams.
Success metrics include alert response time reduction, false alarm rate (<20%), and initial downtime reductions. Establish model retraining procedures and performance monitoring.
Phase 3: Enterprise Integration (Months 13-24)
Scale across all critical equipment, implement advanced analytics (RUL prediction, maintenance optimisation), and integrate with supply chain systems for automatic parts ordering.
Target outcomes include 50-80% downtime reduction, 20-40% maintenance cost savings, and improved equipment life extension.
Successful predictive maintenance requires robust data infrastructure to handle continuous sensor streams and AI engineering expertise to build reliable ML pipelines. Many organizations also benefit from CTO advisory services to align predictive maintenance initiatives with broader digital transformation goals.
Getting Started with Predictive Maintenance
Predictive maintenance with machine learning delivers significant value for Australian manufacturers willing to invest in proper implementation. Success requires technical expertise, organisational commitment, and realistic expectations about implementation timelines.
Start with a focused pilot on critical equipment where failures cause significant business impact. Invest in robust data infrastructure and feature engineering before pursuing advanced ML algorithms. Engage maintenance teams early and often — their domain expertise proves invaluable for feature selection and alert validation.
The 84% downtime reduction achieved in our mining case study demonstrates the transformative potential of well-implemented predictive maintenance systems. However, results depend heavily on data quality, model selection, and organisational commitment to the implementation process.
Ready to explore predictive maintenance for your operation? Start a conversation with our AI engineering team to discuss your specific challenges and implementation approach.
James Liu
Lead Data Engineer at Horizon Labs. Builds the data plumbing AI runs on — dbt pipelines, vector stores, feature platforms. Twelve years across Australian financial services, mining, and logistics. Believes data quality work is the highest-leverage AI investment most teams underspend on, and writes about why.


