Context Engineering for LLM Apps: Beyond Prompt Templates
Prompt templates are where LLM applications start. Context engineering is what makes them work reliably in production. This article covers the four core levers — retrieval, compression, memory, and ordering — and how to build a context pipeline that produces consistent, cost-efficient model behaviour at scale.

Prompt templates were the starting point. For production LLM applications, they are rarely enough.
Most teams building on top of large language models begin the same way: craft a system prompt, slot in some user input, call the API, and iterate on wording until the outputs look reasonable. That works for demos. It breaks down when you need consistent, cost-efficient behaviour across thousands of real conversations, documents, and users.
Context engineering is the discipline that fills that gap.
What Is Context Engineering?
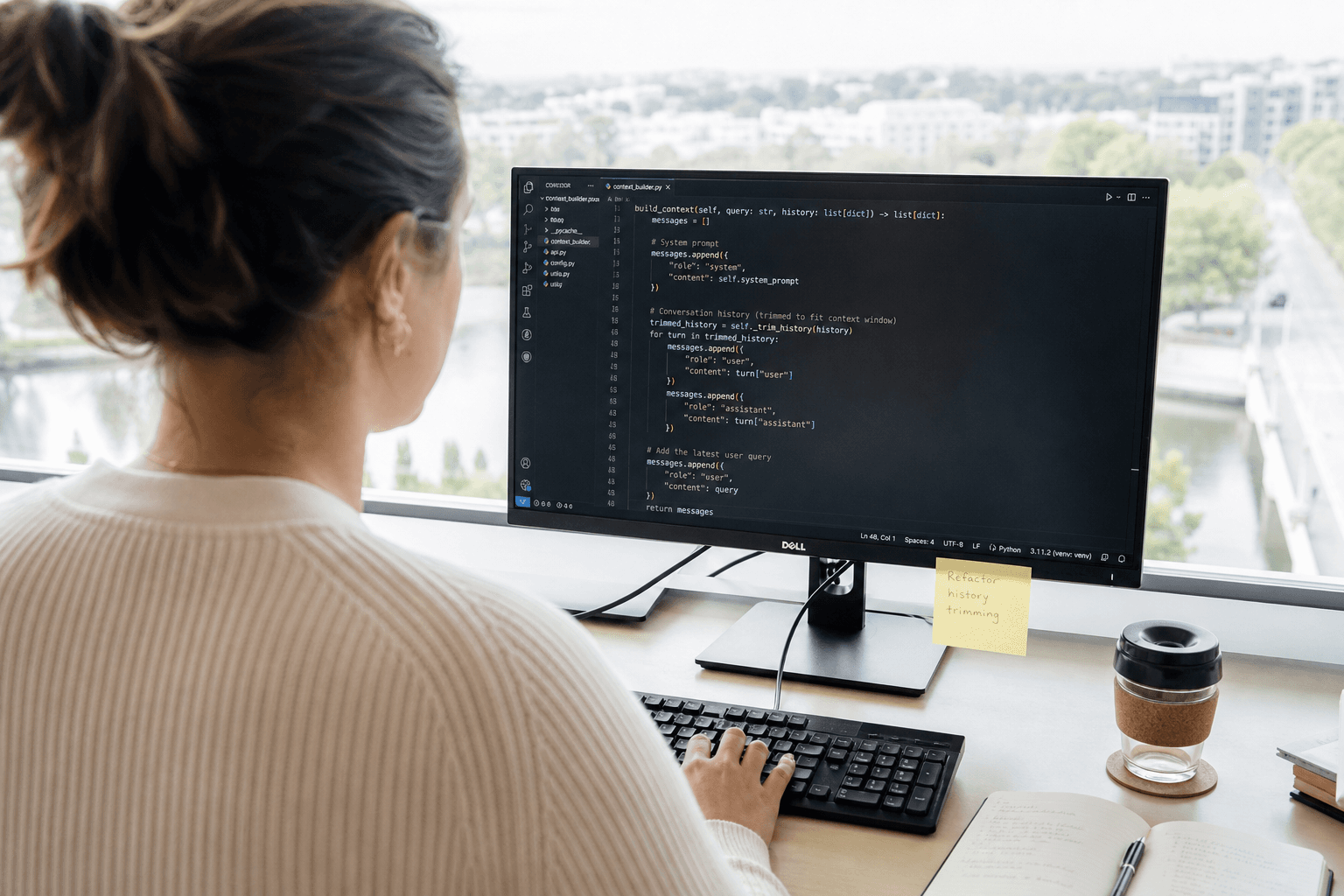
Context engineering is the practice of deliberately constructing what goes into a model's context window — not just the instruction template, but the retrieved knowledge, the conversation history, the compressed background, and the ordering of every token the model sees before it generates a response. Where prompt engineering asks "what should I say?", context engineering asks "what should the model know, in what form, and in what order?"

The context window is a finite, expensive resource. How you fill it determines output quality, latency, and cost — often more than the model you choose.
Why Prompt Templates Fall Short in Production
Prompt templates fail at scale for several compounding reasons. A fixed template cannot adapt to what a specific user actually needs in a given moment. It cannot incorporate knowledge that post-dates the model's training cutoff. And it wastes tokens on context that is irrelevant to the current query.
In production, the problems tend to surface as:
- Hallucination on proprietary data — the model has no grounding in your documents, policies, or records, so it invents plausible-sounding answers.
- Context overflow — naively concatenating conversation history hits token limits quickly, forcing either truncation (losing important context) or expensive long-context models.
- Inconsistent behaviour — without a structured, deterministic context pipeline, small changes in input produce large swings in output quality.
- Cost inefficiency — sending the same large static prompt on every call is wasteful when most of that content is irrelevant to the specific query.
Each of these is a context problem, not a prompt-wording problem.
The Four Levers of Context Engineering
Reliable LLM applications are built by managing four distinct layers of what enters the context window.
1. Retrieval: Getting the Right Knowledge In
Retrieval is the process of dynamically selecting relevant content from an external knowledge base and injecting it into the context window at inference time. Retrieval-Augmented Generation (RAG) is the most widely adopted pattern here: embed a query, search a vector store, and prepend the top-k results to the model's context.
But retrieval quality is where most RAG implementations fail. The core problem is that embedding similarity does not equal relevance. A document can be semantically close to a query without actually answering it. Production retrieval systems typically combine dense vector search with sparse keyword search (hybrid retrieval), apply re-ranking models to score candidates against the specific query, and filter by metadata — document type, recency, access permissions — before anything reaches the context window.
The retrieval layer is also where grounding happens. Retrieved chunks give the model evidence to reason from, which reduces hallucination on domain-specific questions. Platforms like Google Vertex AI treat RAG as a first-class capability with dedicated API resources for grounding and retrieval, which reflects how central this layer has become to production AI architecture.
2. Compression: Spending Tokens Wisely
Not every token you could include should be included. Context compression is the practice of reducing token consumption without losing the information the model actually needs to answer the query.
Compression techniques include:
- Summarisation — replacing verbose conversation history or long documents with a condensed representation. A 10,000-token conversation history might compress to 500 tokens with acceptable information loss for most queries.
- Extractive selection — rather than summarising, extracting only the sentences or paragraphs directly relevant to the current query.
- Prompt caching — some LLM platforms support caching the key-value representation of a static context prefix, so repeated calls with the same system prompt or background documents do not pay the full token cost on every request. This is a meaningful cost lever for high-volume applications.
- Structured condensation — converting unstructured conversation history into structured memory entries (entities, facts, decisions) that are more information-dense per token.
The right compression strategy depends on your latency budget, quality requirements, and call volume. There is no universal answer, which is why this layer requires deliberate design rather than defaults.
3. Memory: Persisting What Matters Across Turns
Memory architecture is how an LLM application maintains continuity across a conversation — or across sessions — without simply concatenating everything into the context window.
Four memory types are commonly discussed in production system design:
| Memory Type | What It Stores | Retrieval | Token Cost |
|---|---|---|---|
| In-context (buffer) | Recent turns verbatim | Always included | High and grows |
| Summarised | Compressed conversation history | Always included | Lower, bounded |
| Episodic | Specific past events or interactions | Retrieved on demand | Low per call |
| Semantic | Extracted facts, entities, preferences | Retrieved on demand | Low per call |
Most production applications use a combination. Recent turns stay in the buffer. Older history is compressed or summarised. Long-term user preferences and extracted facts are stored externally and retrieved when the current query makes them relevant.
The design question is not "how do I give the model memory?" but "what does the model need to remember, and when does it need it?" Answering that question precisely keeps context lean and outputs accurate.
4. Ordering: Sequence Affects Behaviour
LLMs are sensitive to the position of information within the context window. Research has consistently shown that models attend more reliably to content at the beginning and end of the context — the so-called "lost in the middle" effect — and that instruction placement relative to content affects instruction-following behaviour.
Practical ordering principles for production context windows:
- Place the most critical instruction or persona definition first, in the system turn.
- Put retrieved evidence or grounding documents before the user's query where possible, so the model reasons from the evidence rather than generating first.
- If you must include long documents, put the most relevant sections closest to the query.
- Reserve the final tokens before the generation prompt for the specific instruction you most need the model to follow.
Ordering is the most underrated lever in context engineering. It costs nothing in tokens but has a meaningful effect on consistency.
Putting It Together: A Context Pipeline
In a well-engineered LLM application, context construction is a pipeline that runs before every model call. A simplified version looks like this:
- Receive the user query.
- Classify intent and extract key entities — this drives downstream retrieval and memory queries.
- Retrieve relevant documents and semantic memory entries for the classified query.
- Load the recent conversation buffer (last N turns).
- Compress older history into a summarised memory block if it exists.
- Assemble the context window in the correct order: system instruction → background knowledge → compressed history → recent buffer → retrieved evidence → current query.
- Trim to budget: if the assembled context exceeds the token target, apply a priority-based truncation strategy rather than a naive cut.
- Call the model.
This pipeline is deterministic and auditable. When outputs degrade, you can inspect exactly what was in the context window and trace the failure to a specific layer — retrieval quality, compression loss, ordering, or the base instructions.
Context Engineering and Your Architecture
Context pipelines do not exist in isolation. They sit on top of your data infrastructure — vector stores, document stores, relational databases, and event streams — and they integrate with whatever orchestration layer you use to build LLM applications.
This has implications for how you plan AI adoption. Teams that invest in solid data infrastructure before building LLM features find context engineering substantially easier: the knowledge bases exist, they are structured, and retrieval quality is higher because data quality is higher. Teams that skip this step often find themselves rebuilding data foundations mid-project.
The AI engineering work of building a production context pipeline — retrieval, compression, memory, ordering, evaluation — is also more substantial than most initial estimates assume. The model is rarely the hard part. The pipeline that feeds it reliably is.
Evaluation: You Cannot Improve What You Cannot Measure
Context engineering improvements need measurement loops. For each layer:
- Retrieval: measure recall (did the right documents come back?) and precision (did irrelevant documents come back?). Offline evaluation against a labelled query set is the baseline.
- Compression: measure information retention — does a downstream task perform equally well on compressed vs. uncompressed context? Automated benchmarks using a judge model are practical here.
- Memory: measure factual consistency across turns. Does the model correctly recall information stated earlier in the session?
- Ordering: A/B test context assembly strategies against a consistent set of queries and measure task completion or output quality.
Without evaluation infrastructure, context engineering becomes guesswork. Building eval into the development loop from the start — not as an afterthought — is one of the clearest differentiators between prototype-quality and production-quality LLM systems.
What This Means for Technical Leaders
If you are a CTO or Head of Engineering planning an LLM application, context engineering has several practical implications for resourcing and architecture decisions.
First, the skills required are broader than "prompt writing". A production context pipeline requires engineers who understand information retrieval, embedding models, vector databases, token budgeting, and evaluation methodology — as well as the model APIs themselves.
Second, context engineering is where you pay for poor data foundations. If your documents are unstructured, inconsistently formatted, or living across fifteen different systems, retrieval quality will reflect that. The context pipeline surfaces data quality problems that were previously invisible.
Third, this is not a one-time build. Context pipelines need ongoing tuning as your knowledge base grows, your user base diversifies, and model behaviour evolves. Treating it as a product — with measurement, iteration, and ownership — is more realistic than treating it as a configuration exercise.
If you are still at the stage of evaluating whether and how to build LLM-powered features, the AI product strategy question — what problem are we solving, and what architecture serves that problem — is where context engineering decisions become consequential. Getting those decisions right early is significantly cheaper than reversing them later.
For a broader view on what it takes to take AI from concept to production, our insights section covers the engineering and strategy questions that come up most often in practice.
Context engineering is one of the more technically demanding aspects of building reliable LLM applications — and one of the most frequently underestimated. If you are working through how to architect a context pipeline for your application, or trying to diagnose why your current LLM feature behaves inconsistently, start a conversation with our team. We work with engineering teams across Australia on exactly these problems.
Chris Kerr
Partner at Horizon Labs, an AI product consultancy and venture studio. A commercially focused product and technology leader with 20+ years building and scaling digital platforms, teams, and businesses across SaaS, travel, eCommerce, logistics and transport, and digital marketing — operating at the intersection of product, engineering, and data. Writes about platform strategy, AI transformation, modern data ecosystems, and the operational discipline that separates AI demos from AI products.


