Real-Time Data Pipelines: When You Need Them and When You Don't
Real-time data pipelines process data with minimal latency, but most mid-market businesses don't actually need them. Understanding when batch processing suffices versus when streaming is truly required can save significant complexity and cost.
Real-Time Data Pipelines: When You Need Them and When You Don't
Real-time data pipelines process and move data with minimal latency, typically within seconds or milliseconds of generation. While they sound compelling, most mid-market businesses don't actually need them — and building them when batch processing would suffice is an expensive mistake that diverts resources from more impactful initiatives.
The key is understanding your actual latency requirements versus perceived urgency. True real-time needs are rarer than most organisations think, and the complexity overhead is significant.
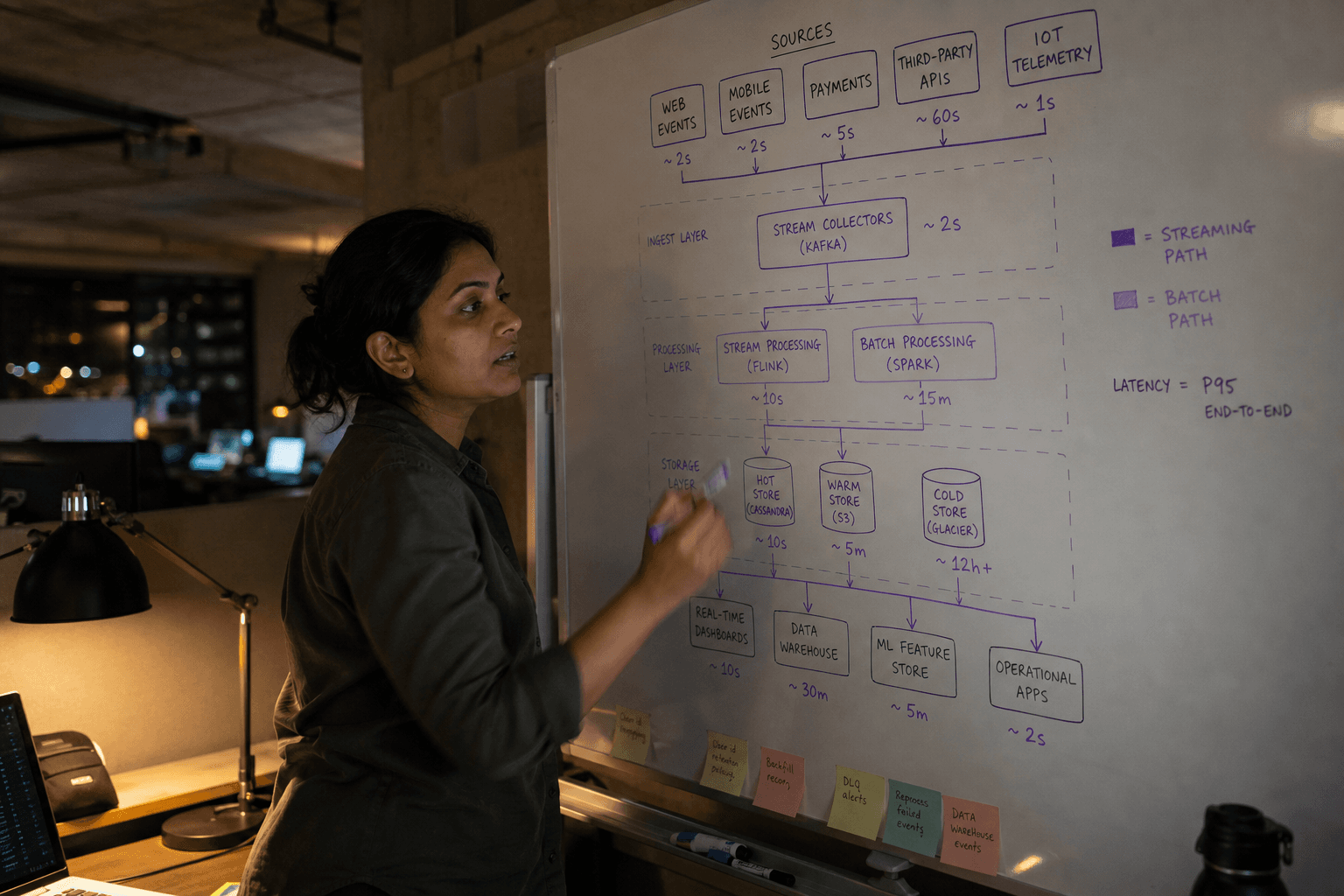
What Are Real-Time Data Pipelines?
A real-time data pipeline is a system that ingests, processes, and delivers data with minimal delay — typically measured in seconds or milliseconds. Unlike batch processing that handles data in scheduled chunks, real-time pipelines process events as they occur, maintaining continuous data flow from source to destination.

Real-time pipelines use streaming technologies like Apache Kafka, AWS Kinesis, or Azure Event Hubs to handle continuous data flows. They require different architectural patterns, monitoring approaches, and operational expertise compared to traditional batch systems.
Batch vs Streaming vs Micro-Batch: Understanding Your Options
| Processing Type | Latency | Complexity | Cost | Best For |
|---|---|---|---|---|
| Batch | Hours to days | Low | Low | Reporting, analytics, ETL |
| Micro-batch | Minutes to hours | Medium | Medium | Near real-time dashboards |
| Streaming | Seconds to milliseconds | High | High | Fraud detection, IoT monitoring |

Batch processing handles data in scheduled intervals — daily, hourly, or on-demand. It's simple, reliable, and cost-effective for most business intelligence and reporting needs.
Micro-batch processing splits data into small batches processed frequently, offering a middle ground between batch simplicity and streaming responsiveness. Tools like Apache Spark support this approach.
Streaming processing handles individual events as they arrive, providing the lowest latency but requiring significant infrastructure and operational overhead.
When Do You Actually Need Real-Time Data?
Real-time data pipelines are justified when immediate action is required based on incoming data. The business impact of delayed processing must outweigh the significant complexity and cost overhead.
Legitimate real-time use cases include:
- Fraud detection in financial transactions
- Industrial equipment monitoring and automated shutdowns
- Live bidding and pricing in marketplaces
- Real-time personalisation in high-traffic applications
- IoT sensor data triggering immediate responses
- Live chat and notification systems
Common false real-time requirements:
- Executive dashboards (hourly updates are usually sufficient)
- Business intelligence reporting
- Customer analytics and segmentation
- Inventory management (unless stock-outs cost thousands per minute)
- Most marketing automation workflows
The Hidden Costs of Real-Time Architecture
Real-time data pipelines introduce significant operational complexity that many organisations underestimate. The infrastructure costs are just the beginning.
Technical complexity multiplies with streaming systems. You need expertise in distributed systems, stream processing frameworks, and complex monitoring. Debugging streaming applications is fundamentally harder than batch jobs.
Operational overhead increases substantially. Real-time systems require 24/7 monitoring, sophisticated alerting, and rapid incident response. Data quality issues become harder to detect and fix.
Cost implications extend beyond infrastructure. Streaming platforms consume more resources than batch systems, and the specialised talent required commands premium salaries.
How to Evaluate Your Real-Time Requirements
Start with business impact analysis rather than technical assumptions. Ask specific questions about latency tolerance and consequences.
Define your actual SLA requirements. What happens if data is 5 minutes old? 1 hour? 24 hours? Quantify the business impact of each scenario.
Consider your data volume and velocity. High-volume, high-velocity data sources may justify streaming architecture, while periodic data updates likely don't.
Assess your team's capabilities. Do you have engineers experienced with streaming technologies? The operational maturity to support 24/7 systems?
Start with simpler solutions. Often, more frequent batch jobs or micro-batch processing meets business requirements without streaming complexity.
Building Your Data Infrastructure Strategy
Most mid-market businesses should start with robust batch processing and evolve toward real-time capabilities only when genuine business requirements emerge.
Begin with solid data infrastructure foundations. Establish reliable data ingestion, storage, and batch processing before considering streaming. Poor data quality undermines real-time systems even more than batch systems.
Implement monitoring and observability first. You need comprehensive monitoring for batch systems anyway, and it becomes even more critical for streaming.
Consider hybrid approaches. Many organisations successfully combine batch processing for heavy analytics workloads with selective real-time processing for specific use cases.
The path forward depends on your specific business context, technical capabilities, and genuine latency requirements. Most organisations benefit more from reliable, well-monitored batch systems than from complex real-time infrastructure they can't properly maintain.
If you're evaluating your data infrastructure needs or considering real-time capabilities, our data infrastructure team can help you assess requirements and build the right foundation for your business. We specialise in pragmatic data architecture that grows with your needs without over-engineering for theoretical requirements.
James Liu
Lead Data Engineer at Horizon Labs. Builds the data plumbing AI runs on — dbt pipelines, vector stores, feature platforms. Twelve years across Australian financial services, mining, and logistics. Believes data quality work is the highest-leverage AI investment most teams underspend on, and writes about why.


