How to Evaluate RAG System Quality: Metrics That Actually Matter
Comprehensive guide to evaluating RAG system quality in production. Learn essential metrics for retrieval precision, answer faithfulness, and operational performance to ensure reliable AI-powered applications.

How to Evaluate RAG System Quality: Metrics That Actually Matter
RAG evaluation metrics determine whether your retrieval-augmented generation system delivers reliable, accurate responses in production. While accuracy matters, comprehensive RAG quality assessment requires measuring retrieval precision, answer faithfulness, response relevance, and operational performance across your entire pipeline.
Why Traditional Accuracy Metrics Fall Short for RAG
Traditional accuracy metrics measure whether generated answers match expected outputs, but RAG systems have unique failure modes that simple accuracy cannot capture. A system might retrieve irrelevant documents but generate a plausible-sounding answer, or retrieve perfect information but fail to synthesise it correctly.
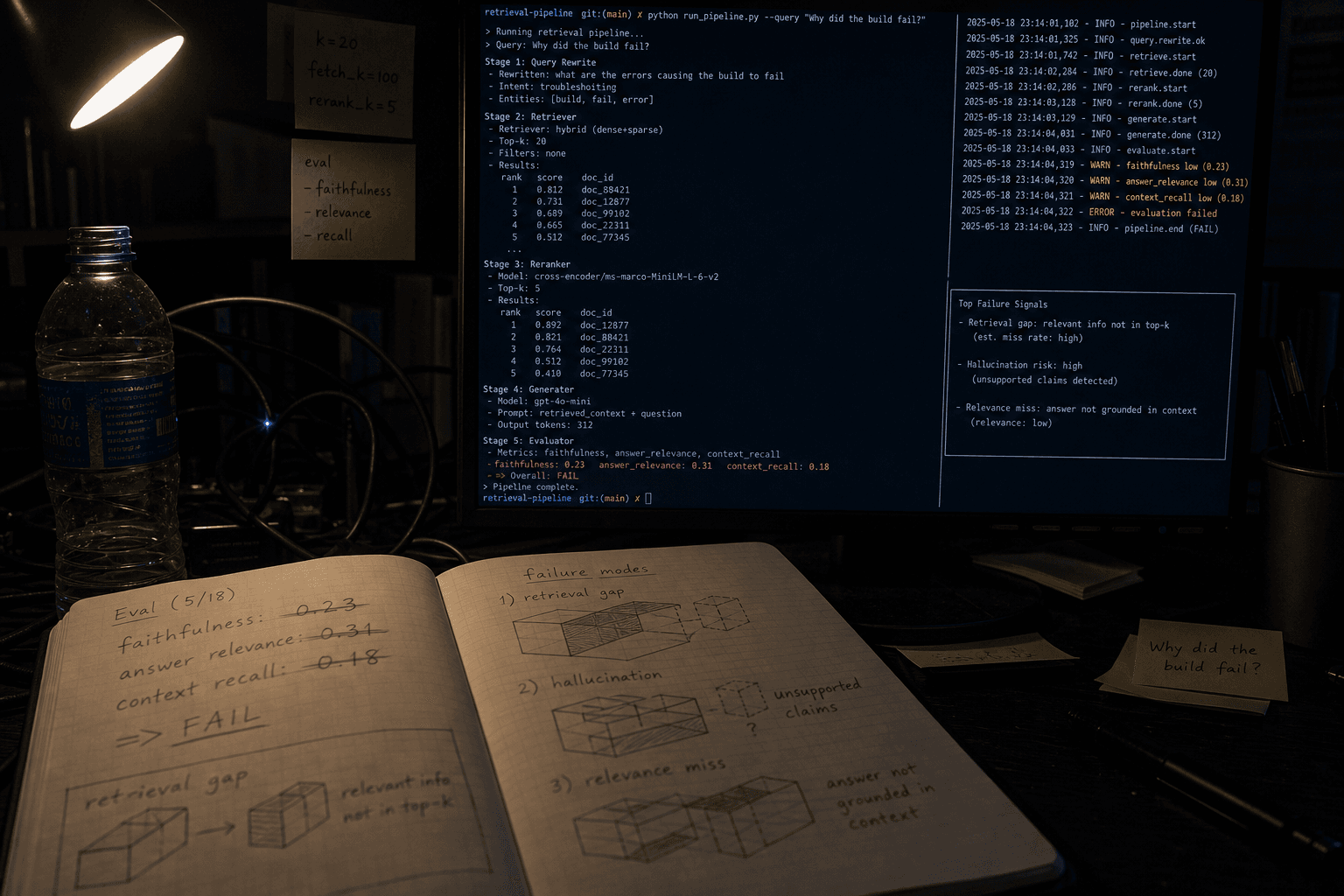
RAG systems fail in three distinct ways: retrieval failures (wrong documents), generation failures (poor synthesis), or relevance failures (off-topic responses). Each requires different metrics to detect and measure.
Core RAG Evaluation Metrics
Retrieval Precision and Recall
Retrieval precision measures how many retrieved documents actually contain information relevant to the query. High precision means your retrieval system isn't flooding the generator with noise, while recall ensures you're not missing critical information.
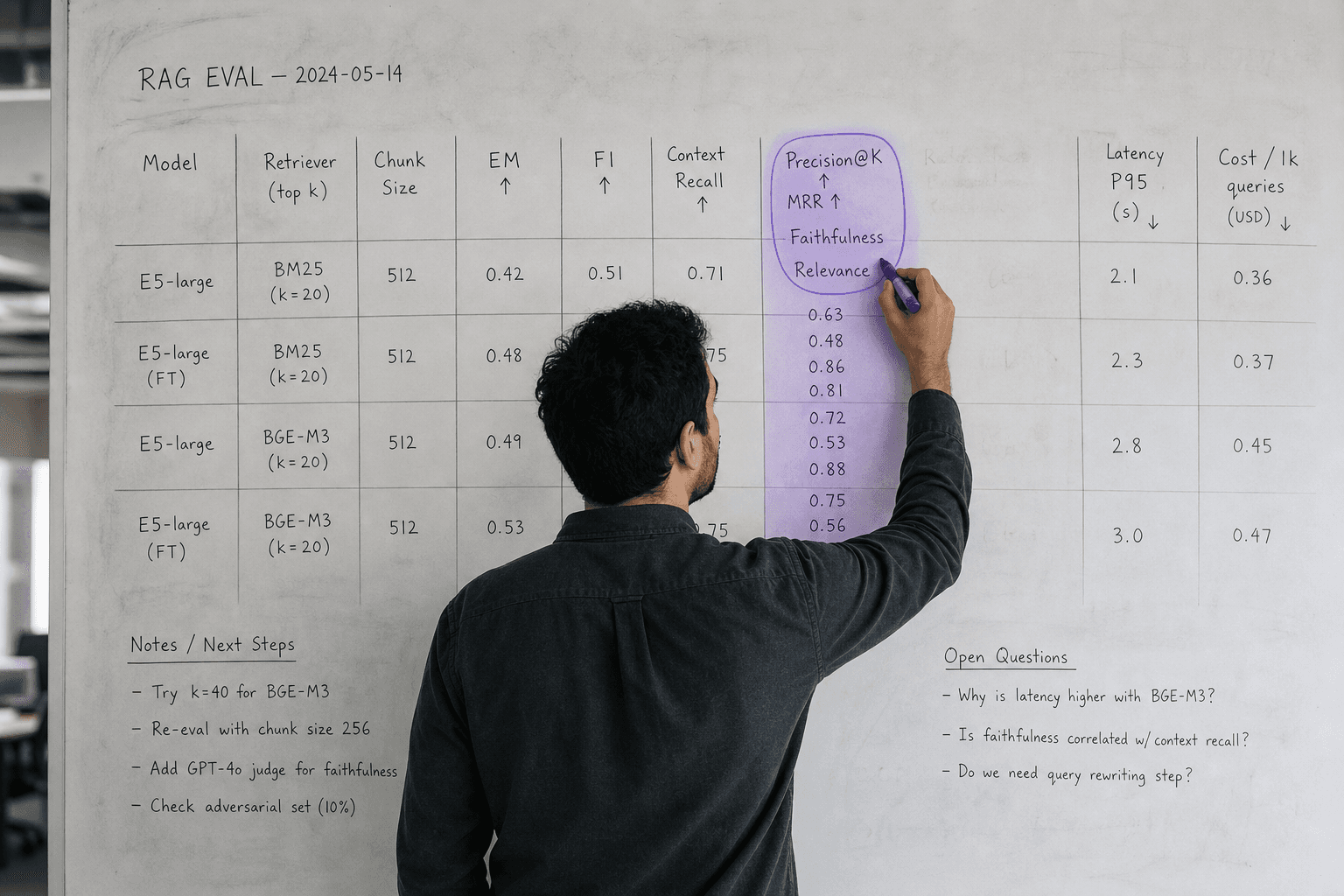
Precision@K evaluates the percentage of top-K retrieved documents that are relevant. For production systems, measure precision at your actual retrieval limit — if you retrieve 5 documents per query, measure precision@5.
Mean Reciprocal Rank (MRR) captures how quickly your system finds the first relevant document. Early relevant results improve generation quality and reduce processing costs.
Answer Faithfulness
Answer faithfulness measures whether generated responses accurately reflect the information in retrieved documents, without hallucination or contradiction. Faithfulness evaluation typically compares generated answers against source documents using semantic similarity or fact-checking models.
Implement faithfulness scoring by breaking answers into atomic claims and verifying each claim against retrieved context. This granular approach helps identify specific failure patterns in your generation pipeline.
Response Relevance
Response relevance evaluates whether generated answers actually address the user's question, regardless of factual accuracy. An answer can be factually correct but completely irrelevant to the query.
Measure relevance using semantic similarity between the query and generated response, or train classifiers to identify on-topic versus off-topic responses for your specific domain.
Operational Metrics for Production RAG
Latency and Performance
Response latency directly impacts user experience and system scalability. Measure end-to-end latency from query to response, plus individual component latencies for retrieval, generation, and post-processing.
Track P95 and P99 latencies alongside averages — tail latency matters for user experience. Monitor how latency scales with document corpus size and query complexity.
Cost Per Query
Cost per query encompasses retrieval costs (embedding computation, vector database queries), generation costs (LLM API calls, token usage), and infrastructure overhead. Understanding true query costs enables informed decisions about model selection and architecture optimisation.
Monitor token usage patterns — longer retrieved contexts increase generation costs but might improve answer quality. This trade-off requires measurement to optimise effectively.
Building Production RAG Evaluation Suites
Automated Evaluation Pipeline
Production RAG systems require continuous evaluation as data and user behaviour evolve. Build automated evaluation pipelines that run regularly against representative query sets, measuring all core metrics simultaneously.
Create evaluation datasets that reflect real user queries, not synthetic test cases. Sample actual user queries periodically and have domain experts create ground-truth answers and relevance judgments.
Human-in-the-Loop Evaluation
Automated metrics cannot capture all aspects of RAG quality. Implement human evaluation workflows for subjective qualities like answer helpfulness, tone appropriateness, and domain-specific accuracy requirements.
Rotate human evaluators regularly and use inter-annotator agreement scores to ensure consistent evaluation standards. Combine human judgments with automated metrics for comprehensive quality assessment.
A/B Testing Framework
Deploy RAG system changes through controlled A/B tests, measuring both automated metrics and user behaviour changes. Track downstream metrics like user satisfaction, task completion rates, and engagement patterns.
Implement statistical significance testing for evaluation metrics — small improvements in automated scores should translate to measurable user experience improvements.
Choosing Metrics for Your Use Case
Different RAG applications require different evaluation priorities. Customer support systems typically prioritise faithfulness and relevance to ensure accurate responses, while research applications might emphasise recall to avoid missing critical information.
Technical documentation systems require high precision to avoid overwhelming users with irrelevant results. Content generation applications balance relevance with fluency and originality requirements.
Consider your specific business requirements when selecting primary evaluation metrics. Start with faithfulness and relevance as foundational metrics, then add domain-specific measurements based on user feedback and business outcomes.
Advanced RAG Quality Considerations
Context Window Utilisation
Measure how effectively your system uses available context windows. High-quality RAG systems maximise information density in retrieved contexts while maintaining generation quality.
Track context utilisation ratios and correlate with answer quality metrics. Underutilised context suggests retrieval precision issues, while over-packed context might hurt generation coherence.
Multi-turn Conversation Quality
For conversational RAG applications, evaluate consistency across dialogue turns. Measure whether the system maintains contextual awareness and provides coherent responses throughout extended interactions.
Track conversation-level metrics like topic drift, contradiction detection, and context retention across turns. These measurements require specialised evaluation frameworks beyond single-query metrics.
Australian Market Considerations for RAG Systems
Australian businesses implementing RAG systems face specific regulatory and operational requirements. Privacy regulations like the Privacy Act 1988 influence how organisations can collect and process user queries for evaluation purposes.
Data sovereignty requirements may affect where evaluation data can be stored and processed. Many Australian organisations prefer keeping evaluation datasets within national boundaries, influencing infrastructure and tooling decisions.
Regional language patterns and business contexts require localised evaluation datasets. Australian English variations, industry terminology, and cultural references need representation in your evaluation suite to ensure production quality.
Implementing RAG Evaluation at Scale
Successful RAG evaluation requires systematic measurement from development through production. Establish baseline metrics before system deployment, then continuously monitor performance degradation over time.
Integrate evaluation metrics into your ai engineering workflow, treating quality measurement as essential as functional testing. Automated alerts should trigger when core metrics fall below acceptable thresholds.
Develop evaluation expertise within your team or partner with specialists who understand both the technical requirements and business context of your RAG applications. Quality measurement is not a one-time activity but an ongoing operational requirement.
Production RAG systems represent significant business investments. Proper evaluation frameworks protect that investment by ensuring consistent performance, identifying improvement opportunities, and enabling data-driven optimisation decisions.
Building effective RAG evaluation requires balancing automated measurement with human judgment, operational metrics with quality scores, and development-time testing with production monitoring. The specific metrics matter less than comprehensive, consistent measurement aligned with your business requirements.
Need help implementing RAG evaluation frameworks for your Australian business? Our ai product strategy team specialises in production AI systems that deliver measurable business value. Get in touch to discuss your specific evaluation requirements.
Sarah Mitchell
Principal AI Engineer at Horizon Labs. Specialises in production LLM systems — RAG architectures, fine-tuning pipelines, and the evaluation harnesses that prove a model still works six months after launch. Eight years in machine learning, the last four shipping AI into Australian financial services and healthcare. PhD-level depth, founder-level pragmatism.


