MLOps Explained: How Production AI Stays Reliable After Launch
MLOps ensures AI models remain accurate and reliable in production through continuous monitoring, automated retraining, and governance frameworks. Learn how to detect model drift, implement monitoring pipelines, and build automated retraining systems that keep production AI performing at peak effectiveness.

MLOps Explained: How Production AI Stays Reliable After Launch
MLOps (Machine Learning Operations) is the practice of deploying, monitoring, and maintaining AI models in production environments to ensure they remain accurate, reliable, and compliant over time. Unlike traditional software that degrades predictably, AI models can silently fail as real-world data changes, making MLOps essential for any organisation running AI at scale.
Why AI Models Fail in Production
AI models that work perfectly in development can fail spectacularly in production. A recommendation engine trained on 2022 customer data might struggle with 2024 behaviour patterns. A fraud detection model may miss new attack vectors. Unlike traditional bugs that crash visibly, model degradation happens silently — your AI keeps running while quietly becoming less effective.
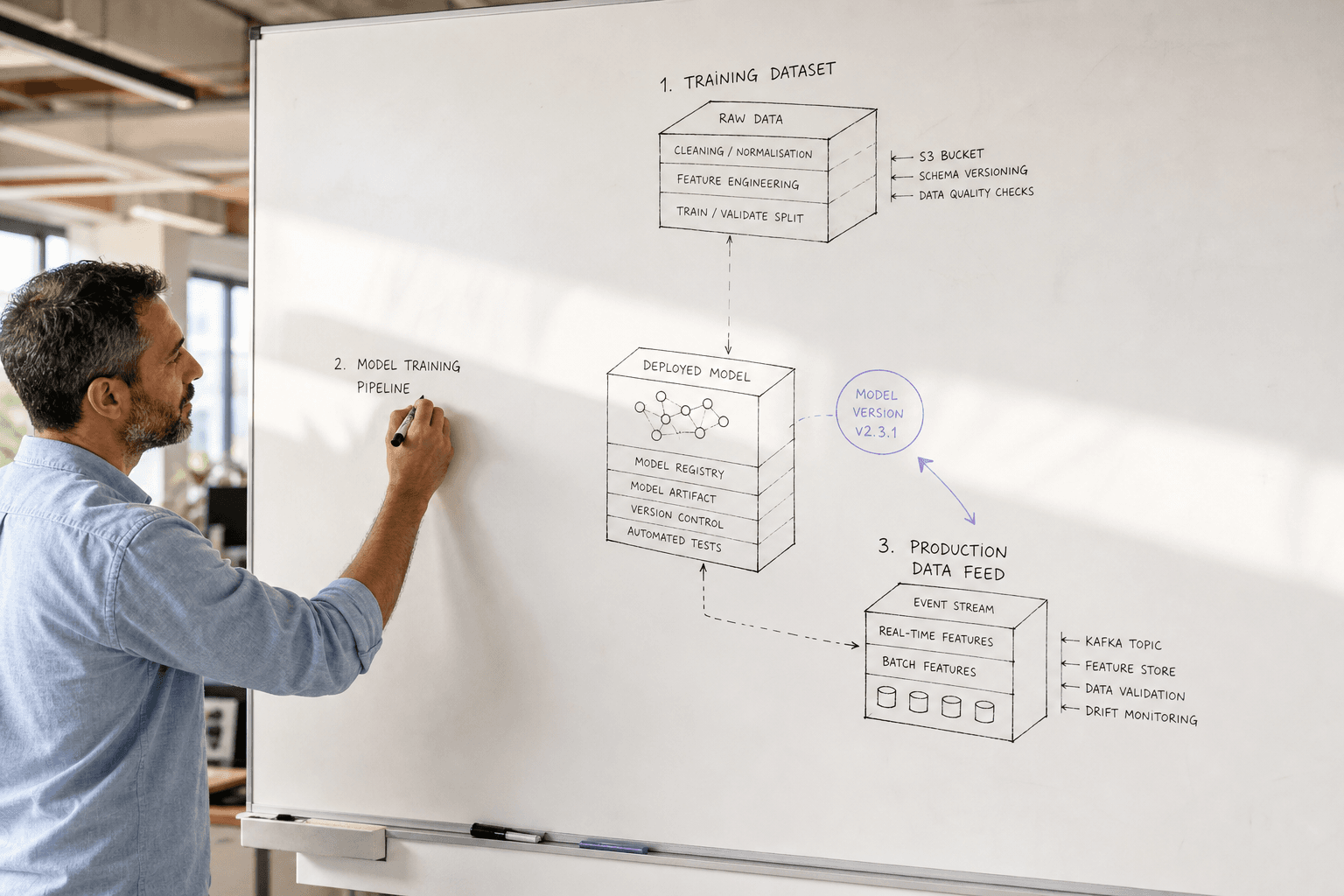
The core challenge is model drift: the gap between training data and real-world data widens over time. Customer preferences shift, market conditions change, new competitors emerge. Your model, frozen at the moment of training, cannot adapt without intervention.
Australian businesses face unique drift challenges. Seasonal patterns differ dramatically — a retail model trained on Melbourne data might struggle in Darwin. Regulatory changes like the Consumer Data Right create new data patterns. Economic shifts affect customer behaviour differently across states.
The Four Pillars of MLOps Monitoring
Model Performance Monitoring
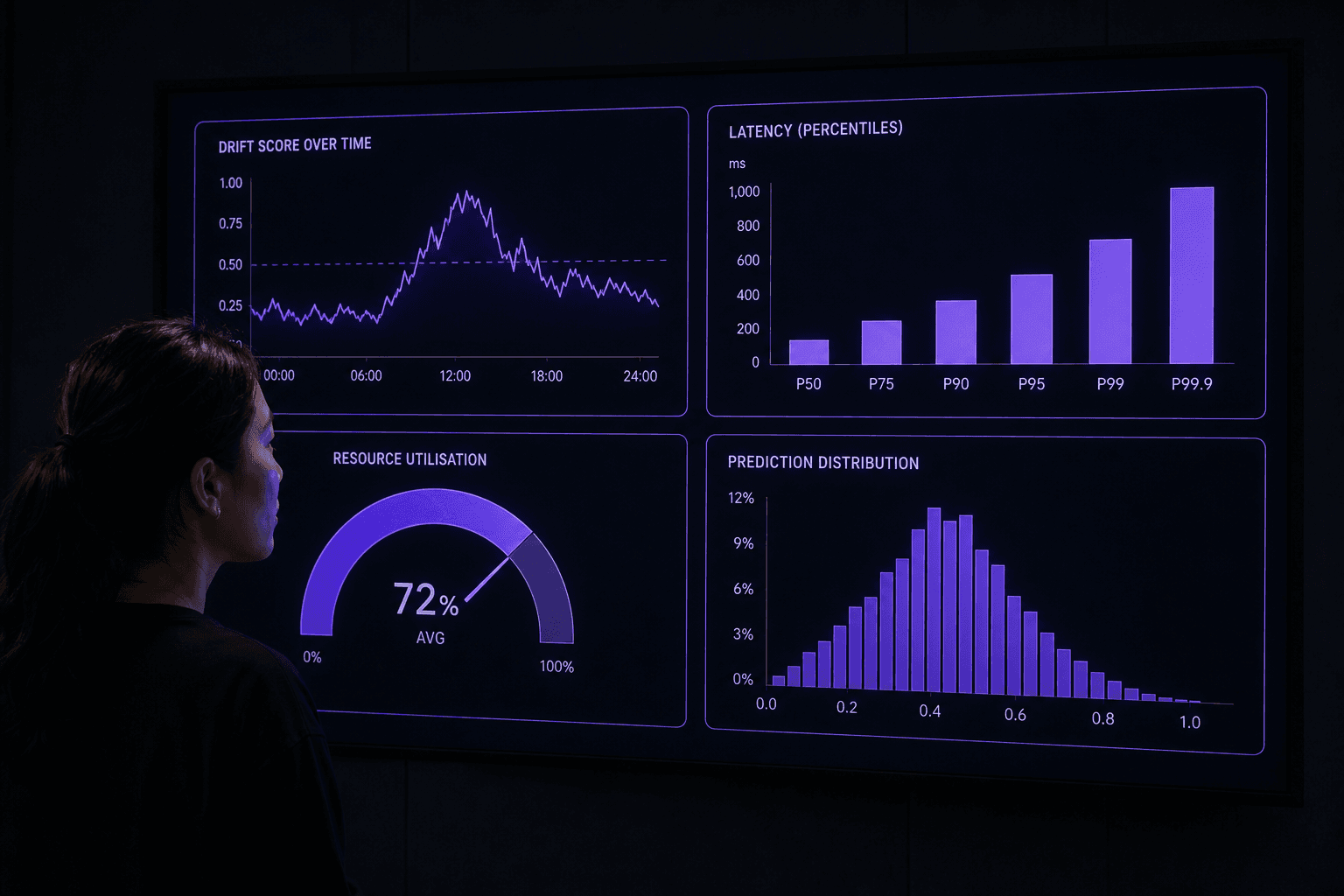
Model performance monitoring tracks how well your AI performs its actual task over time. For a customer churn model, this means tracking prediction accuracy. For a recommendation engine, this means measuring click-through rates and conversion rates.
Key metrics include:
- Accuracy drift: How prediction accuracy changes over time
- Precision and recall: Whether the model maintains balance between false positives and false negatives
- Business metrics: Revenue per prediction, customer satisfaction scores, operational efficiency gains
Set up automated alerts when accuracy drops below defined thresholds. A 5% accuracy drop might trigger investigation. A 10% drop might trigger emergency retraining.
Data Drift Detection
Data drift occurs when incoming production data differs statistically from training data. If your model was trained on customers aged 25-45 but production traffic shifts to 18-30, performance will degrade even if individual predictions seem reasonable.
Data drift monitoring compares production data distributions against training baselines using:
- Statistical tests: Kolmogorov-Smirnov tests for continuous variables, chi-square tests for categorical variables
- Distance metrics: Population Stability Index (PSI) or Jensen-Shannon divergence to measure distribution shifts
- Feature-level monitoring: Track each input feature separately to identify which variables drive drift
Australian retail models commonly experience geographic drift as customer bases shift between cities, or seasonal drift as tourism patterns change post-COVID.
Latency and Infrastructure Monitoring
AI models in production must respond within acceptable timeframes while managing computational costs. A fraud detection model that takes 10 seconds to evaluate a transaction is useless. A recommendation engine that crashes during peak traffic defeats its purpose.
Monitor:
- Response times: 95th percentile latency, not just averages
- Throughput: Requests per second under different load conditions
- Resource utilisation: CPU, memory, and GPU usage patterns
- Cost tracking: Cloud compute costs per prediction, storage costs for model artifacts
Implement circuit breakers that fallback to simpler rules when ML services are overloaded. Better to serve basic recommendations than crash entirely.
Prediction Drift and Output Monitoring
Prediction drift occurs when model outputs change pattern even when inputs remain stable. A credit scoring model might gradually become more conservative, approving fewer loans despite similar applications. This suggests internal model degradation rather than external data changes.
Track:
- Output distributions: Are prediction confidence scores shifting?
- Decision boundaries: Is the model changing its classification thresholds?
- Prediction stability: Do similar inputs generate consistent outputs over time?
Automated Retraining Pipelines
Manual model updates cannot keep pace with production requirements. Automated retraining pipelines continuously update models as new data becomes available, ensuring predictions remain accurate without constant human intervention.
A robust retraining pipeline includes:
Data validation: Automatically check new training data for quality issues, schema changes, and statistical anomalies. Reject batches that fail validation rather than training on corrupted data.
Automated feature engineering: Apply the same transformations used in initial training to new data. Version control feature pipelines to ensure consistency.
Model training and validation: Train candidate models on updated datasets, then validate against holdout data and production scenarios.
A/B testing: Deploy new models to a subset of traffic, comparing performance against existing models before full rollout.
Rollback capabilities: Maintain previous model versions and instantly rollback if new models underperform.
Australian organisations must consider regulatory requirements. Financial services models may require approval before deployment. Healthcare models need audit trails. Retail models should respect privacy legislation changes.
AI Governance and Responsible AI
Production AI requires governance frameworks ensuring models remain fair, explainable, and compliant throughout their lifecycle. This goes beyond technical monitoring to encompass ethical and regulatory considerations.
Model Explainability
Business stakeholders need to understand why models make specific predictions. Regulatory bodies may require explanations for automated decisions. Customers deserve transparency about AI-driven recommendations or approvals.
Implement explainability tools like:
- SHAP (SHapley Additive exPlanations): Quantifies each feature's contribution to individual predictions
- LIME (Local Interpretable Model-agnostic Explanations): Explains individual predictions through local approximations
- Feature importance tracking: Monitor which features drive model decisions over time
Bias Monitoring and Fairness
AI models can perpetuate or amplify biases present in training data. A hiring model trained on historical data might discriminate against women. A credit model might unfairly penalise certain postcodes.
Continuously monitor for:
- Demographic parity: Equal outcomes across protected groups
- Equalized odds: Equal true positive and false positive rates across groups
- Calibration: Prediction confidence matches actual outcomes across demographics
Australian anti-discrimination legislation requires organisations to prevent AI bias. The Australian Human Rights Commission provides guidance on algorithmic fairness.
Audit Trails and Compliance
Maintain comprehensive records of model training data, feature engineering steps, hyperparameter choices, and deployment decisions. Regulatory audits require explaining how models evolved and why specific decisions were made.
Document:
- Model lineage: Which data sources and preprocessing steps created each model version
- Change management: Who approved model updates and why
- Performance history: How model accuracy and fairness metrics changed over time
- Incident response: How quickly teams detected and resolved model failures
MLOps Maturity: From Manual to Automated
| Stage | Characteristics | Tools | Risk Level |
|---|---|---|---|
| Manual | Sporadic model updates, no monitoring, manual deployment | Notebooks, basic deployment | High |
| Basic | Simple monitoring, scheduled retraining, version control | MLflow, basic CI/CD | Medium |
| Intermediate | Automated drift detection, A/B testing, governance processes | Kubeflow, DataDog, Weights & Biases | Medium-Low |
| Advanced | Fully automated pipelines, real-time monitoring, explainable AI | Custom platforms, enterprise MLOps suites | Low |
Most Australian organisations operate at Manual or Basic stages. Moving to Intermediate requires dedicated MLOps engineering but delivers significant reliability improvements.
Getting Started with MLOps
Start with monitoring before automation. You cannot improve what you do not measure.
Week 1-2: Implement basic model performance monitoring. Track accuracy metrics for your most critical AI application.
Week 3-4: Add data drift detection. Compare production inputs against training data distributions.
Week 5-8: Build automated alerting when performance or drift thresholds are exceeded.
Month 2-3: Implement automated retraining for less critical models. Start with simple trigger-based approaches.
Month 4-6: Add governance frameworks, audit trails, and bias monitoring as regulatory requirements dictate.
Prioritise based on business impact. A model driving $1M revenue deserves more sophisticated MLOps than an internal efficiency tool.
Common MLOps Pitfalls to Avoid
Over-monitoring: Tracking hundreds of metrics creates alert fatigue. Focus on metrics that predict actual business problems.
Premature automation: Automating broken manual processes creates automated broken processes. Perfect your workflow manually first.
Ignoring edge cases: Models fail most dramatically on unusual inputs. Test edge cases explicitly.
Treating MLOps as purely technical: MLOps requires collaboration between data scientists, engineers, and business stakeholders. Technical solutions alone are insufficient.
Underestimating complexity: Production MLOps is genuinely difficult. Plan for 3-6 month implementation timelines for mature capabilities.
MLOps Success in Australian Context
Australian organisations succeeding with MLOps share common patterns:
Start with high-value, low-risk applications: Perfect MLOps on internal tools before customer-facing AI.
Embed compliance early: Australian privacy and discrimination laws are strict. Build governance into MLOps from day one.
Plan for geographic distribution: Models serving Perth customers may need different monitoring than those serving Sydney customers.
Leverage cloud infrastructure: Azure, AWS, and GCP offer mature MLOps tools. Do not build everything from scratch.
Invest in MLOps engineering: Dedicated MLOps engineers, distinct from data scientists or traditional DevOps, are essential for production AI.
MLOps is not optional for production AI. Models degrade silently and fail spectacularly without proper monitoring, retraining, and governance. The question is not whether to implement MLOps, but how quickly you can build these capabilities before model drift impacts your business.
Ready to build reliable production AI? Start a conversation about MLOps implementation — we help Australian organisations deploy monitoring, automation, and governance that keeps AI systems running smoothly.
Sarah Mitchell
Principal AI Engineer at Horizon Labs. Specialises in production LLM systems — RAG architectures, fine-tuning pipelines, and the evaluation harnesses that prove a model still works six months after launch. Eight years in machine learning, the last four shipping AI into Australian financial services and healthcare. PhD-level depth, founder-level pragmatism.


