Data Quality for AI: Why Garbage In Still Means Garbage Out
Poor data quality is the fastest way to turn a promising AI project into an expensive failure. Learn how to assess if your data is AI-ready and implement a practical framework for data quality: profiling, validation, monitoring, and remediation.

Data Quality for AI: Why Garbage In Still Means Garbage Out
Poor data quality is the fastest way to turn a promising AI project into an expensive failure. While organisations focus on selecting the right algorithms and models, they often overlook the foundation that determines success: the quality of their data.
The "garbage in, garbage out" principle has never been more critical. AI systems amplify the patterns in your data—including the bad ones. A model trained on incomplete, biased, or inconsistent data will make incomplete, biased, or inconsistent predictions at scale.
What Makes Data AI-Ready?
AI-ready data meets four core criteria: completeness, consistency, accuracy, and timeliness. Data must be complete enough for the model to learn meaningful patterns, consistent in format and structure across sources, accurate in its representation of reality, and current enough to reflect the business environment where the model will operate.
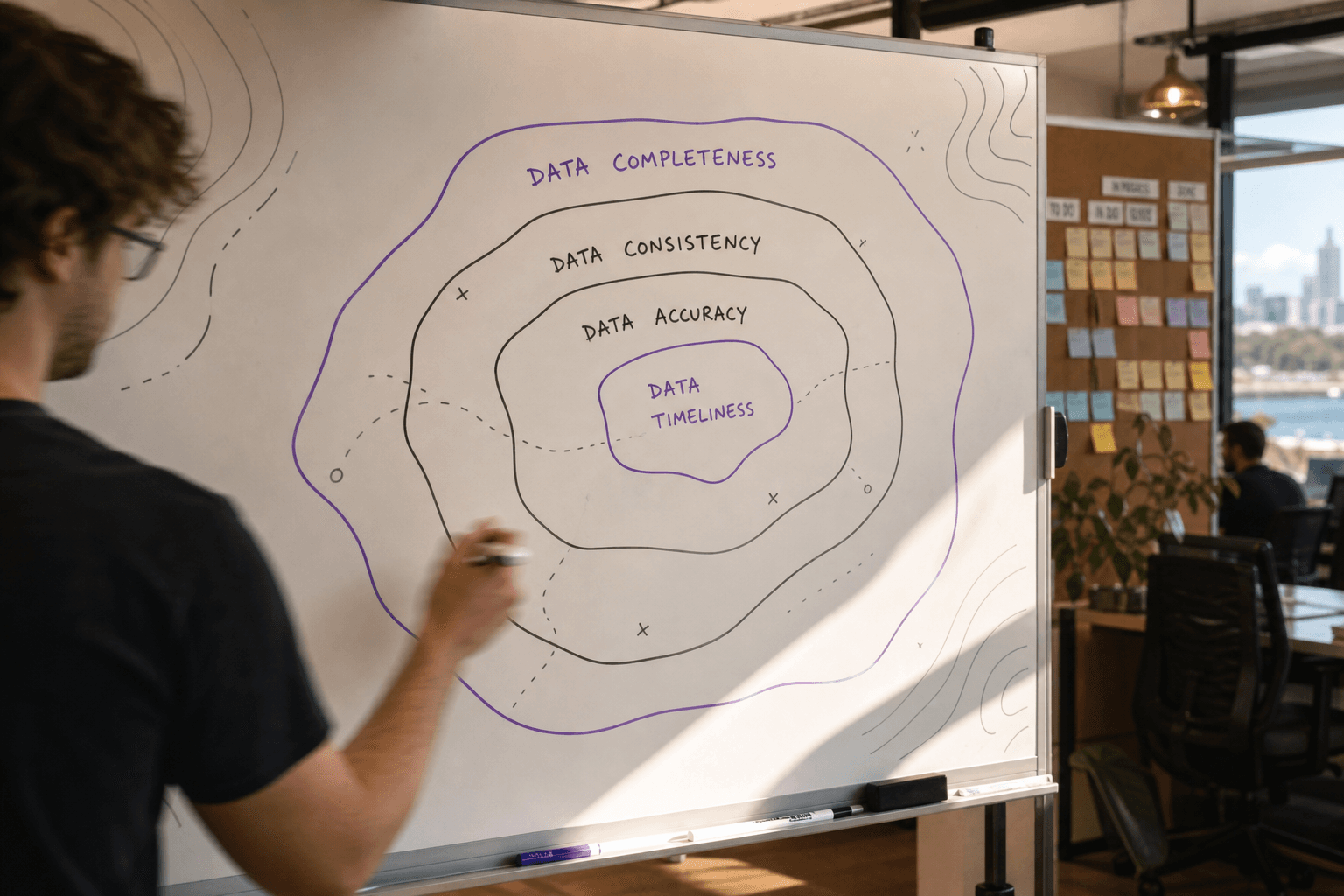
Unlike traditional analytics that can work with imperfect data through manual adjustments and business intuition, AI systems require systematic data quality at every layer. Machine learning models cannot distinguish between genuine patterns and artifacts created by poor data quality—they learn from whatever you feed them.
Common Data Quality Issues That Break AI Projects
Missing or incomplete data creates blind spots in model training. When 30% of your customer records lack industry classification, your AI recommendation engine cannot learn industry-specific patterns, leading to generic suggestions that miss the mark.

Inconsistent data formats confuse machine learning algorithms. Customer names stored as "John Smith" in one system and "Smith, John" in another appear as different entities to the model, fragmenting customer profiles and reducing prediction accuracy.
Outdated information trains models on historical patterns that no longer apply. Pricing data from pre-pandemic supply chains will mislead demand forecasting models operating in today's market conditions.
Data entry errors and duplicates introduce noise that drowns out genuine signals. A single product listed multiple times with slight variations teaches the model incorrect associations and inflates certain patterns.
Biased sampling creates models that work well for some segments but fail for others. Training data dominated by metropolitan customers will produce location recommendation models that underperform in regional markets.
A Practical Data Quality Framework for AI
Successful AI implementations follow a systematic approach to data quality: profile, validate, monitor, and remediate.
Data Profiling: Understanding What You Have
Data profiling reveals the actual state of your data, not what you think it should be. Start by examining completeness rates—what percentage of critical fields contain usable data? Identify value distributions to spot unusual patterns that might indicate data quality issues.
Analyse data relationships between systems. Customer IDs should match across your CRM and billing systems. Product hierarchies should be consistent between inventory and sales data. Mismatches here signal integration issues that will confuse AI models.
Document data lineage to understand how information flows through your systems. Knowing that customer industry classification comes from form submissions, third-party enrichment, and manual updates helps you assess reliability and identify improvement opportunities.
Data Validation: Setting Quality Standards
Validation rules enforce quality standards at the point of entry and throughout data processing pipelines. Business rules might require that all customer records include industry, company size, and geographic location before being used for AI training.
Technical validation catches format errors, range violations, and referential integrity issues. Email addresses should match standard patterns. Dates should fall within reasonable ranges. Foreign keys should reference valid records in related tables.
Statistical validation identifies outliers and anomalies that might indicate data errors or genuinely unusual cases worth investigating. A sudden spike in order values might reveal a pricing error or a new enterprise customer—both important for different reasons.
Continuous Monitoring: Detecting Quality Drift
Data quality changes over time as business processes evolve, systems are updated, and new data sources are integrated. Monitoring dashboards track completeness rates, format consistency, and statistical distributions to catch quality degradation early.
Set up alerts when quality metrics fall below acceptable thresholds. If customer industry classification completeness drops from 95% to 85%, investigate whether a form field was accidentally removed or a data integration broke.
Monitor model performance metrics alongside data quality indicators. A correlation between declining prediction accuracy and increasing missing data rates points to quality issues rather than model problems.
Remediation: Fixing What's Broken
Remediation strategies range from automated fixes to process improvements. Missing values might be filled using business rules (new customers default to "prospect" status) or statistical methods (median values for numerical fields).
Duplicate detection and merging algorithms can consolidate customer records scattered across systems. However, be cautious with automated merging—false positives can destroy valid data relationships.
Some remediation requires human judgment. When product descriptions conflict between systems, subject matter experts need to determine the authoritative version. Build these review processes before you need them urgently.
Assessing Your Organisation's AI Data Readiness
| Assessment Area | Questions to Ask | Quality Indicators |
|---|---|---|
| Data Completeness | What percentage of records contain all required fields? | >90% completeness for critical fields |
| Data Consistency | Are formats standardised across systems? | Consistent naming, units, and structures |
| Data Accuracy | How do you verify information correctness? | Regular validation against authoritative sources |
| Data Timeliness | How fresh is your data? | Updates reflect business reality within acceptable lag |
| Data Integration | Can you easily combine data from multiple sources? | Clear entity relationships and matching keys |
| Data Governance | Who owns data quality decisions? | Defined roles, processes, and escalation paths |
Start with a focused assessment of data you plan to use for your first AI project. It's better to have high-quality data for a narrow use case than mediocre data across your entire organisation.
Building Data Quality into AI Projects from Day One
Successful AI projects treat data quality as a feature requirement, not an afterthought. Include data profiling and quality assessment in project discovery phases. Budget time and resources for data remediation—it typically takes longer than expected.
Establish quality gates in your data infrastructure that prevent poor-quality data from reaching AI models. Models trained on clean data perform better and require less ongoing maintenance.
Create feedback loops between model performance and data quality metrics. When prediction accuracy degrades, check for data quality changes first. Often, fixing a data pipeline issue is faster and more effective than retraining models.
The Cost of Poor Data Quality in AI
Poor data quality multiplies throughout AI systems. A model that makes incorrect predictions 20% of the time due to training data issues will make thousands of incorrect decisions daily when deployed at scale.
The business impact extends beyond accuracy metrics. Customer-facing AI that provides wrong recommendations damages trust and brand reputation. Internal AI that mis-prioritises leads wastes sales team time on low-value prospects.
Remediation costs grow exponentially with time. Fixing data quality issues during development costs hours. Fixing them after production deployment costs weeks of model retraining, testing, and careful rollout.
Getting Started: Your Data Quality Action Plan
Begin with a targeted data quality assessment focused on your first AI use case. Profile the specific datasets involved rather than attempting organisation-wide data quality improvements.
Establish baseline quality metrics and monitoring for critical data elements. Set realistic improvement targets—moving from 70% to 85% completeness is often more valuable than pursuing perfect data.
Invest in data quality tooling and processes that scale with your AI ambitions. Manual data cleaning doesn't scale to production AI systems handling thousands of records daily.
Data quality isn't a one-time project—it's an ongoing capability that enables AI success. Organisations that build strong data quality foundations from the start ship AI products faster and maintain them more easily.
If you're assessing your organisation's AI data readiness or building data quality processes for AI projects, we can help you establish the right foundation.
James Liu
Lead Data Engineer at Horizon Labs. Builds the data plumbing AI runs on — dbt pipelines, vector stores, feature platforms. Twelve years across Australian financial services, mining, and logistics. Believes data quality work is the highest-leverage AI investment most teams underspend on, and writes about why.


