Data Infrastructure for AI: Why Most AI Projects Fail
85% of AI projects fail before models are built due to poor data infrastructure. Learn why data pipelines, warehousing, and governance determine AI success — and how to build incrementally for real outcomes.
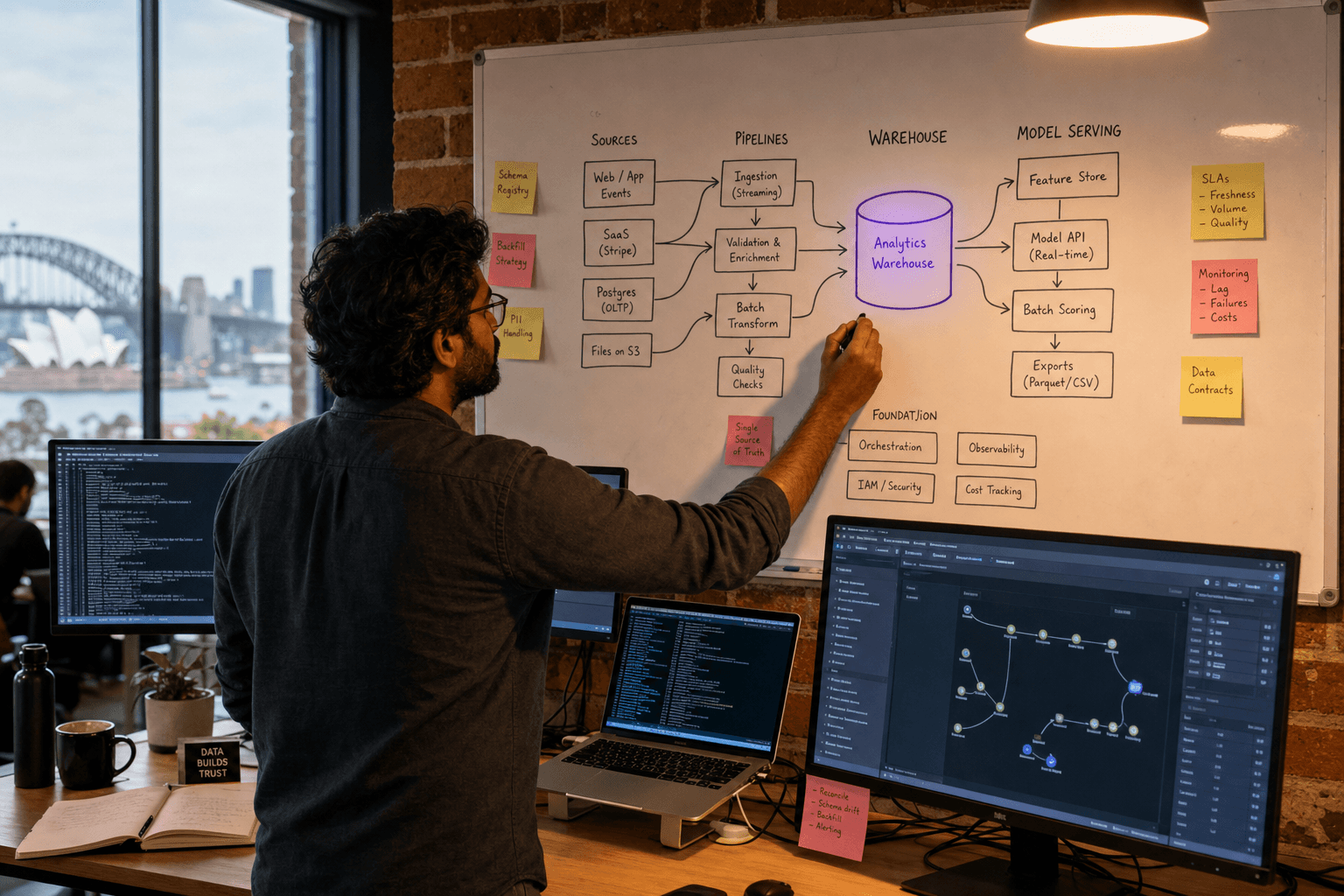
Data Infrastructure for AI: Why Most AI Projects Fail Before the Model Is Built
Data infrastructure for AI is the foundation that determines whether your AI project delivers value or fails spectacularly. Most organisations rush to hire data scientists and build models, only to discover their data is scattered, unreliable, or simply unusable. According to Gartner, 85% of AI projects fail to deliver business value — and most fail before a single model is trained.
The culprit? Poor data infrastructure. You cannot build reliable AI on unreliable data pipelines, siloed storage systems, and absent governance frameworks. Yet this is exactly what most companies attempt.
The Hidden Infrastructure Gap That Kills AI Projects
AI projects fail because organisations underestimate the infrastructure required to move from data to insight. Building machine learning models is the visible 20% of AI implementation. The invisible 80% is data infrastructure: pipelines that reliably collect and transform data, warehousing systems that store it accessibly, and governance frameworks that ensure quality and compliance.

Consider a typical scenario: your marketing team wants to predict customer churn. The model is straightforward — Random Forest, XGBoost, nothing exotic. But the data lives in Salesforce, your ERP system, Google Analytics, support tickets in Zendesk, and financial records in Xero. Each system has different schemas, update frequencies, and data quality issues.
Without proper data infrastructure, your data science team spends 80% of their time on data wrangling instead of model development. Worse, models trained on inconsistent data produce unreliable predictions that damage business confidence in AI.
The Australian Data Challenge
Australian companies face additional complexity with privacy regulations (Privacy Act 1988), data sovereignty requirements, and compliance frameworks like the Australian Accounting Standards Board's AASB S2. Your data infrastructure must handle these requirements from day one, not as an afterthought.
What AI-Ready Data Infrastructure Actually Means
AI-ready data infrastructure is a system where data flows reliably from source systems to models in production, with quality controls and governance built in. This means five core capabilities working together:

1. Automated Data Pipelines
Data pipelines automatically extract, transform, and load data from source systems into your warehouse or lake. Manual data exports kill AI projects because they are unreliable, time-consuming, and do not scale.
Effective pipelines handle:
- Schema evolution: When source systems change field names or types
- Data validation: Automated checks for completeness, accuracy, and consistency
- Error recovery: What happens when a pipeline fails at 2 AM
- Monitoring: Real-time alerts when data quality degrades
2. Centralised Data Storage
Modern data architecture combines data warehouses for structured analytics with data lakes for raw storage. Azure Synapse, AWS Redshift, or Snowflake provide the warehouse layer, while S3 or Azure Data Lake handles raw files, logs, and unstructured data.
The key is federation — your data scientists need a single interface to query data regardless of where it lives. Tools like Databricks or Spark provide this unified access layer.
3. Data Quality Frameworks
Data quality is not a one-time fix but an ongoing discipline. Data quality frameworks include:
- Completeness: Are required fields populated?
- Accuracy: Do values match expected ranges and formats?
- Consistency: Are values consistent across systems?
- Timeliness: Is data fresh enough for your use case?
- Validity: Do values conform to business rules?
Frameworks like Great Expectations or dbt tests automate these checks and fail pipelines when quality thresholds are not met.
4. Data Governance and Lineage
Data governance establishes who can access what data, how it can be used, and how changes are tracked. This includes:
- Access controls: Role-based permissions with audit trails
- Data lineage: Tracking how data flows from source to model
- Change management: Controlled processes for schema or pipeline changes
- Compliance automation: Ensuring GDPR, Privacy Act, or industry standards are met
Tools like Apache Atlas, Collibra, or cloud-native solutions provide governance automation.
5. Model Operations (MLOps)
MLOps bridges the gap between model development and production deployment. This includes:
- Feature stores: Centralised repository of ML features with versioning
- Model registries: Version control for trained models
- Automated deployment: CI/CD pipelines for models
- Monitoring: Tracking model performance and data drift in production
How to Assess Your Current Data Estate
Before building AI infrastructure, you need an honest assessment of your current data landscape. Most organisations are further behind than they think.
The Data Infrastructure Maturity Model
| Level | Description | Characteristics | AI Readiness |
|---|---|---|---|
| 1 - Ad Hoc | Manual exports, spreadsheets | No automation, high error rates | Not ready |
| 2 - Basic ETL | Simple scheduled jobs | Basic pipelines, limited monitoring | Limited |
| 3 - Modern Pipelines | Automated with quality checks | Reliable, monitored, some governance | Ready for pilots |
| 4 - AI-Native | End-to-end automation | Feature stores, MLOps, full governance | Production ready |
Assessment Questions
Ask yourself these questions to gauge readiness:
Data Access: Can your data team access all relevant data sources without manual requests? How long does it take to get new data sources connected?
Data Quality: What percentage of your data requires manual cleaning before analysis? How often do you discover data quality issues after analysis begins?
Change Management: When source systems change, how long until your analytics are updated? Do you have automated testing to catch breaking changes?
Governance: Can you trace any data point back to its source? Do you know which systems contain personal data subject to privacy regulations?
Performance: How long does it take to refresh your core datasets? Can your systems handle the volume required for machine learning?
Building AI-Ready Data Infrastructure Incrementally
The key to successful data infrastructure is incremental development focused on specific business outcomes. Start with one high-value use case and build infrastructure that supports it, then expand.
Phase 1: Foundation (Months 1-3)
Start with data warehouse fundamentals:
- Choose your stack: Cloud-native solutions (Snowflake, BigQuery, Synapse) provide faster time-to-value than on-premise deployments
- Identify priority data sources: Focus on 3-5 sources that support your first AI use case
- Build basic pipelines: Use tools like Azure Data Factory, AWS Glue, or Fivetran for initial ETL
- Establish data quality baseline: Implement basic validation rules and monitoring
Phase 2: Quality and Governance (Months 2-4)
Overlap with Phase 1 to build quality into your foundation:
- Implement data quality framework: Deploy Great Expectations or similar tooling
- Establish governance policies: Define access controls and approval workflows
- Create data catalogue: Document schemas, business definitions, and lineage
- Automate compliance: Build privacy controls and audit trails
Phase 3: AI-Native Capabilities (Months 4-6)
Add machine learning specific infrastructure:
- Deploy feature store: Centralise feature engineering and versioning
- Implement MLOps pipeline: Automated model training, testing, and deployment
- Add monitoring: Track data drift, model performance, and business metrics
- Scale infrastructure: Optimise for larger datasets and more complex models
Common Implementation Pitfalls
Over-engineering: Do not build a data lake before you have use cases. Start simple and add complexity as needed.
Ignoring governance: Security and compliance are not optional extras. Build them in from day one.
Perfectionism: You do not need perfect data to start. Build incrementally and improve quality over time.
Tool proliferation: Resist the urge to evaluate every new data tool. Choose a stack and optimise it.
The ROI of Proper Data Infrastructure
Investing in data infrastructure pays dividends across your entire organisation, not just AI projects.
Reduced time-to-insight: Proper pipelines reduce the time from question to answer from weeks to hours. Data teams spend time analysing instead of wrangling.
Improved decision quality: Clean, timely data leads to better business decisions. Australian retail company Bunnings credits their data infrastructure with enabling rapid COVID-19 response decisions.
Regulatory compliance: Automated governance reduces compliance risk and audit costs. One ASX-listed client reduced quarterly compliance reporting from 40 hours to 4 hours through automation.
AI success rates: Companies with mature data infrastructure see 3x higher AI project success rates according to McKinsey research.
Building robust data infrastructure requires both strategic planning and technical execution. Our AI engineering teams work with organisations to design data pipelines that scale with AI workloads, while our data infrastructure specialists implement the warehousing and governance frameworks that prevent project failures. For organisations starting their AI journey, AI product strategy consulting helps align data infrastructure investments with business outcomes from day one.
Getting Started: Your Data Infrastructure Roadmap
Start with assessment: Map your current data sources, quality issues, and gaps. This typically takes 2-4 weeks and provides the foundation for your roadmap.
Choose your first use case: Select an AI project with clear business value and manageable data requirements. Customer segmentation, demand forecasting, or churn prediction are good starting points.
Build incrementally: Resist the urge to boil the ocean. Build infrastructure that supports your first use case, then expand.
Measure success: Track both technical metrics (pipeline reliability, data quality scores) and business outcomes (time-to-insight, decision speed).
Plan for scale: Design your architecture to handle 10x your current data volume and complexity.
Data infrastructure is not glamorous, but it is the foundation that determines whether your AI investments deliver value or waste time and money. Get the infrastructure right, and AI becomes a competitive advantage. Get it wrong, and you join the 85% of failed AI projects.
Ready to assess your data infrastructure and build a roadmap for AI success? We help Australian companies modernise their data estate and implement AI-ready infrastructure. Start a conversation about your data challenges and AI goals.
James Liu
Lead Data Engineer at Horizon Labs. Builds the data plumbing AI runs on — dbt pipelines, vector stores, feature platforms. Twelve years across Australian financial services, mining, and logistics. Believes data quality work is the highest-leverage AI investment most teams underspend on, and writes about why.


