Data Contracts: Stopping Pipeline Breakage Before It Starts
Silent schema drift is one of the most common and costly causes of broken data pipelines and degraded AI models — and it rarely announces itself. Data contracts are the structural mechanism that catches upstream changes before they reach production, enforcing schema, quality, and freshness expectations at the producer level. This post explains what data contracts are, how to implement them with modern tooling, and why they are foundational to reliable AI and analytics infrastructure.

What Is a Data Contract?
A data contract is a formal, versioned agreement between a data producer and a data consumer that defines the expected schema, data types, quality thresholds, and service-level expectations for a dataset. Think of it as an API contract — but for data. When a producer changes a field name, drops a column, or silently shifts a type from integer to string, the data contract is what catches that change before it propagates downstream and breaks a pipeline, corrupts an analytics report, or poisons an AI model's training run.
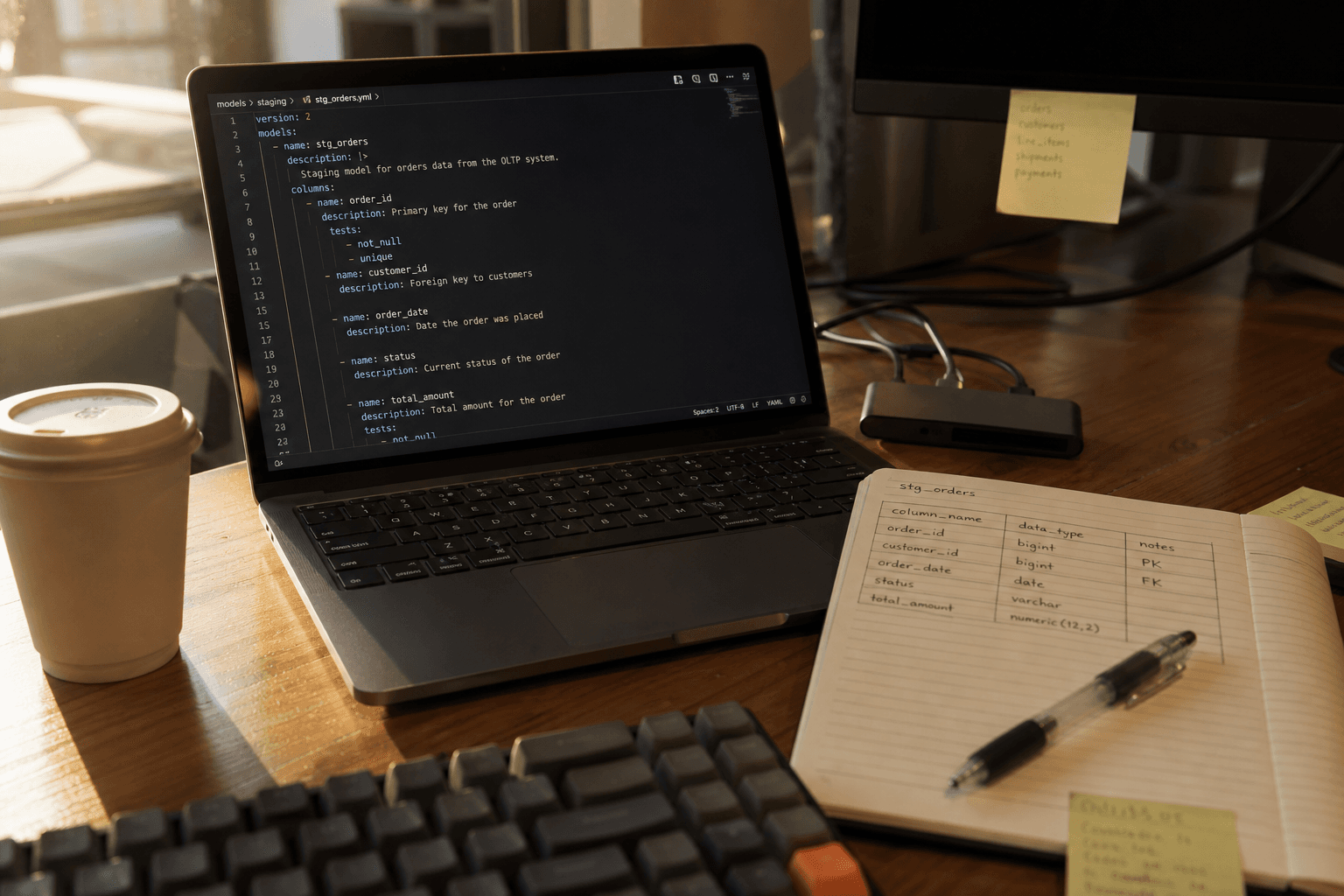
Without contracts, data pipelines operate on trust. A transformation job assumes the upstream table looks the same today as it did last Tuesday. That assumption holds — until it does not.
Why Silent Schema Drift Is the Quiet Killer of Data Pipelines
Silent schema drift is the gradual, unannounced change in the structure or content of a dataset over time. It is called silent because no alarm fires when it happens — the pipeline does not crash immediately. Instead, the change propagates downstream, producing subtly wrong numbers, missing dimensions in a dashboard, or mislabelled training examples that degrade model performance over weeks.

This failure mode is especially dangerous in multi-step pipelines. When data flows through ingestion, transformation, feature engineering, and model serving, an error introduced at step one compounds at every subsequent step. By the time a stakeholder notices the anomaly, tracing it back to the source is a painful, manual exercise. Agentic AI systems — where autonomous agents chain tasks together — are particularly exposed to this pattern: errors in early steps propagate through the full task chain, and observability is harder to maintain across the whole system.
Common causes of silent schema drift include:
- Application teams renaming or retyping database columns without notifying data consumers
- Third-party API providers changing their response payload without versioning the change
- ETL jobs silently coercing nulls or unexpected values rather than failing loudly
- Source system migrations where the new schema is assumed to be equivalent to the old one
What a Data Contract Actually Contains
A well-formed data contract is a machine-readable document that specifies at minimum:
| Element | What It Defines |
|---|---|
| Schema | Field names, data types, nullable flags, and key constraints |
| Quality rules | Acceptable ranges, uniqueness requirements, referential integrity |
| Freshness SLA | How recently the data must have been updated to be considered valid |
| Ownership | The producing team and the consuming team, with named contacts |
| Versioning | How changes are communicated, and what constitutes a breaking change |
| Data classification | Sensitivity level, PII flags, and applicable regulatory obligations |
The data classification element is not optional in the Australian context. The Australian Privacy Principles — specifically APP 10 — require organisations to take reasonable steps to ensure personal information is accurate, up-to-date, and complete. A data contract that includes PII field flags and freshness SLAs is a practical mechanism for meeting that obligation upstream, before personal data reaches analytics or AI workloads.
How to Implement Data Contracts: A Practical Approach
Start with the highest-risk interfaces
Not every dataset in your warehouse needs a contract on day one. Begin with the interfaces that carry the most downstream risk — the datasets that feed production AI models, customer-facing dashboards, or regulatory reporting. Map the producer-consumer relationships for these datasets first and write contracts at those boundaries.
Choose a format and tooling that fits your stack
Data contracts can be expressed in several forms depending on your platform maturity:
- dbt contracts: If your transformation layer runs on dbt, dbt's native contract enforcement lets you declare expected column names and types directly in your model configuration. When an upstream source violates the contract, the dbt run fails loudly rather than silently passing through bad data.
- Great Expectations: A Python-based framework that lets you define and run expectations against datasets — including schema checks, value range validations, and null rate thresholds. Expectations can be run as part of a CI/CD pipeline or on a schedule.
- Soda: A data quality platform that supports contract-style checks written in a declarative YAML syntax, with integrations for common data warehouses and notification channels. Soda is particularly practical for teams that want data quality checks without embedding Python logic.
- Schema registries: For streaming data (Kafka, Kinesis), a schema registry enforces Avro or Protobuf schemas at the producer level, preventing incompatible messages from ever reaching consumers.
The right tool depends on your stack. The important principle is that contract enforcement happens as close to the producer as possible — not at the point of consumption.
Integrate contracts into CI/CD
Data contracts deliver their value when they are enforced automatically, not when they are stored in a wiki and reviewed quarterly. The target state is:
- Contract definitions live in version control alongside the data models and transformation code that depend on them.
- When a producer proposes a schema change, a pull request triggers automated contract validation against downstream consumers.
- Breaking changes — field removals, type changes, mandatory field additions — require an explicit version bump and sign-off from consuming teams before merging.
- Contract checks run on every pipeline execution in CI, failing the pipeline and alerting on-call before bad data reaches production.
This is the same discipline software teams apply to API versioning. The data team is the API team for everyone who depends on their datasets.
Define what a breaking change looks like
Not all schema changes are equal. Teams need an agreed taxonomy before implementing contracts:
- Breaking: Removing a field, changing a field's type, changing a primary key, reducing precision of a numeric field
- Non-breaking: Adding a new nullable field, adding an index, updating documentation
- Deprecation: Marking a field as deprecated with a migration timeline communicated to consumers
Documenting this taxonomy and encoding it into your contract review process prevents the common failure mode where a producer makes what they consider a minor change that cascades into downstream failures.
Data Contracts and AI Governance
For teams building and operating AI systems, data contracts are not just an engineering convenience — they are a governance mechanism. AI governance frameworks increasingly require documentation of training data provenance, model versions, and evaluation results as foundational practices for defensible AI. A data contract provides a verifiable record of what the training dataset was promised to look like at the time a model was trained, which is essential context when investigating model degradation.
This matters practically: if a model's accuracy degrades six months after deployment, the first question is whether the distribution of incoming data has shifted relative to training. With data contracts and contract violation logs in place, you have an audit trail. Without them, you are debugging blind.
For organisations building towards responsible AI practices, data contracts sit at the foundation of the data quality layer that everything else depends on. This is why data infrastructure work at Horizon Labs always includes a conversation about contract enforcement — the most sophisticated ML pipeline is fragile if the data flowing into it is undeclared and unvalidated.
Common Implementation Pitfalls
Contracts as documentation only: A contract stored in Confluence but not enforced in code provides false assurance. The contract must be machine-executable to be effective.
Boiling the ocean: Teams that attempt to retroactively contract every dataset simultaneously rarely finish the exercise. Prioritise by downstream impact and expand incrementally.
No ownership assignment: A contract without a named owner on both the producer and consumer side has no-one responsible for resolving violations. Governance requires accountable humans, not just tools.
Ignoring semantic drift: Schema contracts catch structural changes but not semantic ones — a field called revenue that silently changes its calculation methodology will pass a schema check. Complement schema contracts with data quality checks and domain-level monitoring.
Getting Started: A Phased Approach
For teams building out their data platform or modernising an existing one, a pragmatic starting point looks like this:
Phase 1 — Inventory and risk mapping (two to four weeks): Identify the ten to fifteen datasets that carry the highest downstream risk. Document current schema, producing system, consuming systems, and known quality issues.
Phase 2 — Contract authoring for critical paths (four to six weeks): Write machine-executable contracts for the highest-risk interfaces. Stand up tooling (dbt contracts, Great Expectations, or Soda depending on stack). Run contracts in observation mode — log violations without blocking — to establish a baseline.
Phase 3 — Enforcement and CI integration (ongoing): Move contracts to enforcement mode on critical pipelines. Integrate contract validation into the CI/CD pipeline. Establish a breaking-change review process.
Phase 4 — Expand coverage incrementally: Use pipeline incidents as the trigger for adding new contracts. Each time a schema change breaks something unexpected, a contract goes on that interface.
This phased approach is consistent with how Horizon Labs approaches data infrastructure engagements — establishing solid foundations before layering AI and analytics complexity on top.
The Relationship Between Data Contracts and AI Engineering
Teams moving from analytics workloads into production AI will find that data contracts become load-bearing infrastructure. A model serving real-time predictions has zero tolerance for the kinds of schema surprises that a batch analytics job can absorb. Feature pipelines, training data pipelines, and inference pipelines all need the guarantee that the data they receive matches the schema and quality profile they were built against.
This is one reason why AI engineering work almost always surfaces data contract gaps early in an engagement. It is common to find teams with sophisticated model architectures sitting on top of fragile, uncontracted data pipelines — and the model is only as reliable as the data beneath it.
Summary
Data contracts shift data quality enforcement from reactive — finding out a pipeline broke because a dashboard looks wrong — to proactive, where schema changes are caught at the source before they propagate downstream. For organisations running analytics, AI, or any workload that depends on consistent data, contracts are the structural mechanism that makes reliability repeatable rather than lucky.
The investment is modest relative to the cost of debugging silent failures in production. The tooling is mature. The main requirement is organisational — producers and consumers agreeing to treat their data interfaces with the same discipline they already apply to software interfaces.
If you are building or modernising your data platform and want to ensure your pipelines can support production AI reliably, get in touch. We can help assess where your highest-risk data interfaces are and what a practical contract implementation looks like for your stack.
Chris Kerr
Partner at Horizon Labs, an AI product consultancy and venture studio. A commercially focused product and technology leader with 20+ years building and scaling digital platforms, teams, and businesses across SaaS, travel, eCommerce, logistics and transport, and digital marketing — operating at the intersection of product, engineering, and data. Writes about platform strategy, AI transformation, modern data ecosystems, and the operational discipline that separates AI demos from AI products.


