RAG vs Fine-Tuning: When to Use Each (And When You Don't Need Either)
RAG and fine-tuning serve different purposes in LLM deployment, with distinct cost, performance, and maintenance profiles. Most organisations jump to complex solutions when simple prompt engineering would suffice.

RAG vs Fine-Tuning: When to Use Each (And When You Don't Need Either)
RAG and fine-tuning serve different purposes in LLM deployment, with distinct cost, performance, and maintenance profiles. Most organisations jump to complex solutions when simple prompt engineering would suffice. Here's how to choose the right approach for your use case.
What Are RAG and Fine-Tuning?
RAG (Retrieval-Augmented Generation) is a technique that combines large language models with external knowledge retrieval. Instead of relying solely on the model's training data, RAG systems search relevant documents or data sources and include that context in the prompt. This allows LLMs to access fresh information and domain-specific knowledge without retraining.
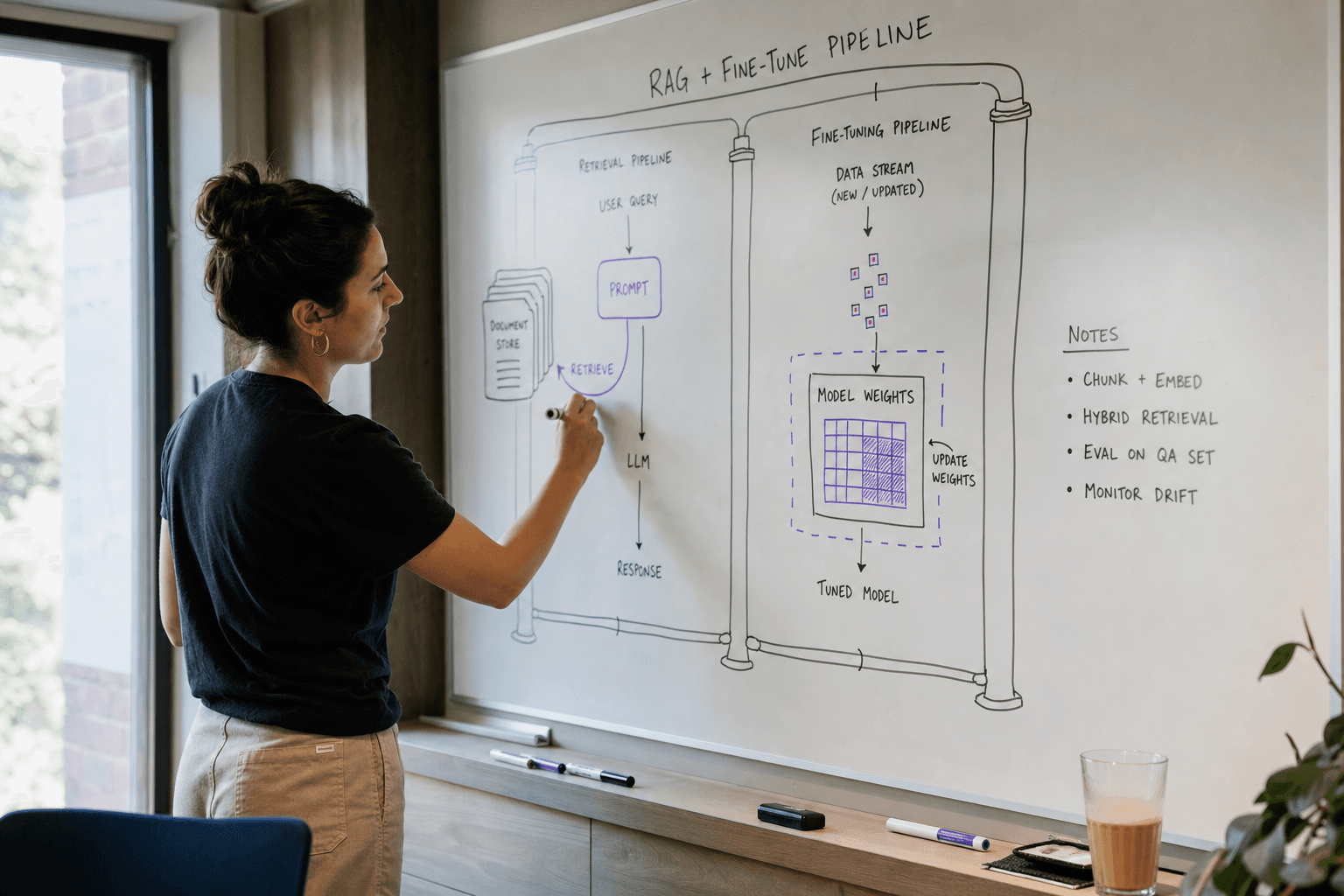
Fine-tuning is the process of taking a pre-trained language model and training it further on domain-specific data. This creates a specialised version of the model that better understands your particular use case, terminology, and response patterns. Fine-tuning modifies the model's weights to improve performance on specific tasks.
Before exploring either approach, consider whether standard prompt engineering meets your needs. Many organisations overcomplicate their AI implementation when clear instructions, examples, and structured prompts deliver sufficient results at a fraction of the cost and complexity.
When RAG Wins: Retrieval, Freshness, and Cost
RAG excels in scenarios requiring access to fresh information, large document repositories, or cost-effective scaling. The technique shines when your knowledge base changes frequently or when you need to maintain accuracy with minimal ongoing investment.
Dynamic Information Requirements
RAG systems handle changing information better than fine-tuned models. If your organisation deals with frequently updated policies, product catalogues, or regulatory documents, RAG can incorporate new information immediately. A fine-tuned model would require retraining every time your knowledge base changes, making RAG the clear choice for dynamic content.
Consider an Australian logistics company managing NHVR regulations, customs requirements, and route optimisations. These change regularly, and a RAG system can query the latest documents without model retraining. The system retrieves relevant sections from current regulations and uses them to inform responses about compliance requirements.
Large-Scale Document Processing
RAG handles massive document repositories efficiently. When processing thousands of documents monthly, RAG's retrieval mechanism scales horizontally — you can add more documents without degrading model performance. Fine-tuning becomes impractical when dealing with 50,000+ documents per month, as the training data size would make fine-tuning prohibitively expensive and slow.
Our experience with mid-market Australian manufacturers shows RAG processing technical documentation, safety procedures, and supplier contracts effectively. The system indexes documents as vector embeddings and retrieves relevant sections based on user queries, maintaining consistent performance regardless of repository size.
Cost-Effectiveness at Scale
RAG systems typically cost less to maintain than fine-tuned models. While initial setup requires vector database infrastructure and embedding generation, ongoing costs remain predictable. Fine-tuning costs escalate with model size and training frequency — GPT-4 fine-tuning can cost thousands per iteration, while RAG systems scale cost-effectively with usage patterns.
| Cost Factor | RAG | Fine-Tuning |
|---|---|---|
| Initial Setup | $5,000-15,000 | $2,000-50,000+ |
| Monthly Maintenance | $500-2,000 | $1,000-10,000+ |
| Scaling Cost | Linear with queries | Exponential with data |
| Update Cost | Near zero | Full retrain cost |
When Fine-Tuning Is Justified: Consistency, Latency, and Scale
Fine-tuning becomes essential when you need consistent behaviour, predictable latency, or specialised reasoning patterns. These scenarios justify the higher cost and complexity of maintaining custom models.
Consistent Output Formatting
Fine-tuning excels at producing consistent output formats, especially for structured data generation or API responses. When your application requires JSON output with specific schemas, fine-tuned models maintain formatting consistency better than RAG systems, which can introduce variability based on retrieved content.
Financial services organisations fine-tune models for risk assessment reports, ensuring outputs always include required fields, follow regulatory formatting, and maintain consistent scoring methodologies. This consistency is harder to achieve with RAG, where retrieved context might influence output structure unpredictably.
Latency-Critical Applications
Fine-tuned models typically respond faster than RAG systems because they eliminate the retrieval step. RAG systems must search vector databases, rank results, and construct prompts before generating responses. Fine-tuned models process queries directly, making them suitable for real-time applications requiring sub-second response times.
Real-time customer support chatbots often benefit from fine-tuning when response speed matters more than access to the latest information. The model can handle common queries instantly without document retrieval overhead.
Domain-Specific Reasoning
Some domains require reasoning patterns that general-purpose models struggle with, even with retrieved context. Legal document analysis, medical diagnosis support, or complex financial modelling may benefit from fine-tuning when the reasoning process itself needs customisation beyond what context injection provides.
Specialised manufacturing quality control systems might fine-tune models to understand defect classification patterns, equipment failure modes, or process optimisation logic that requires domain expertise beyond what RAG context can provide.
The Third Option: Advanced Prompt Engineering
Prompt engineering often delivers 80% of the benefits at 20% of the cost and complexity. Before implementing RAG or fine-tuning, explore advanced prompting techniques: few-shot learning, chain-of-thought reasoning, role-playing, and structured output instructions.
Advanced prompting includes:
- Few-shot examples: Provide 3-5 examples of desired input-output pairs
- Chain-of-thought: Ask the model to show its reasoning process
- Role specification: Define the model's expertise and perspective
- Output formatting: Specify exact JSON schemas or response structures
- Constraint setting: Define what the model should not do or include
Many organisations achieve their goals with carefully crafted prompts that cost nothing beyond base API usage. Test prompt engineering thoroughly before moving to complex solutions.
Decision Matrix: Choosing Your Approach
Use this decision framework to determine the optimal approach:
Start with Prompt Engineering if:
- Budget constraints exist
- Requirements are unclear or changing
- Team lacks ML engineering expertise
- Response time requirements are flexible
- Data volume is manageable manually
Choose RAG when:
- Information freshness is critical
- Document volume exceeds manual management
- Knowledge base changes frequently
- Multiple data sources need integration
- Cost predictability is important
- Team has data engineering capabilities
Consider Fine-Tuning when:
- Output consistency is non-negotiable
- Latency requirements are strict (<500ms)
- Domain reasoning is complex and specialised
- Long-term cost optimisation justifies upfront investment
- Team has ML engineering expertise
- Training data quality is high
Real-World Example: 50K Documents Monthly
Consider an Australian mining company processing 50,000 safety and compliance documents monthly. Each document requires classification, risk assessment, and regulatory mapping.
RAG Implementation:
- Vector database stores document embeddings
- Retrieval system finds relevant safety protocols
- LLM generates risk assessments with current context
- Monthly cost: ~$8,000 (infrastructure + API calls)
- Implementation time: 6-8 weeks
- Maintenance: Minimal, automated document ingestion
Fine-Tuning Approach:
- Custom model trained on safety document patterns
- Consistent risk scoring methodology
- Faster inference times for real-time alerts
- Monthly cost: ~$15,000 (training + inference)
- Implementation time: 12-16 weeks
- Maintenance: Regular retraining as regulations change
Outcome: RAG won for this use case due to regulatory changes requiring fresh context, cost considerations, and the team's data engineering capabilities over ML expertise.
Cost Comparison Analysis
| Scenario | Prompt Engineering | RAG | Fine-Tuning |
|---|---|---|---|
| 1,000 queries/month | $50 | $800 | $2,000 |
| 10,000 queries/month | $500 | $2,500 | $5,000 |
| 100,000 queries/month | $5,000 | $8,000 | $12,000 |
| Dynamic content | ✅ Free updates | ✅ Immediate | ❌ Retrain cost |
| Consistent formatting | ⚠️ Variable | ⚠️ Variable | ✅ Reliable |
| Setup complexity | Low | Medium | High |
Implementation Considerations
Technical Requirements
RAG systems require vector database infrastructure, embedding models, and retrieval optimization. Popular choices include Pinecone, Weaviate, or self-hosted solutions like ChromaDB. Australian data sovereignty requirements may influence database selection.
Fine-tuning needs GPU infrastructure, training pipelines, and model versioning systems. Cloud providers like AWS, Azure, or Google Cloud offer managed services, but costs accumulate quickly with large models and frequent retraining.
Team Expertise
RAG implementations require data engineering skills: database management, API integration, and document processing pipelines. The learning curve is gentler than fine-tuning, making it accessible to more development teams.
Fine-tuning demands ML engineering expertise: training pipeline development, hyperparameter optimization, evaluation metric design, and model deployment. This typically requires specialist hiring or external consulting.
Regulatory Compliance
Australian organisations must consider data residency under the Privacy Act 1988. RAG systems processing local documents may require Australian hosting, affecting infrastructure choices and costs.
Fine-tuned models trained on proprietary data create intellectual property considerations and potential audit requirements. Document your training data lineage and model behaviour for compliance purposes.
Measuring Success
Define clear metrics before implementation:
RAG Metrics:
- Retrieval accuracy: Are relevant documents found?
- Response relevance: Do answers address the query?
- Freshness: How quickly do updates appear in responses?
- Cost per query: Total infrastructure and API costs divided by query volume
Fine-Tuning Metrics:
- Task accuracy: Does the model perform the specific task correctly?
- Output consistency: Are responses formatted predictably?
- Inference latency: Response time from query to answer
- Training efficiency: Cost and time to achieve target performance
Getting Started
Begin with thorough prompt engineering exploration. Many requirements resolve at this level without additional complexity. Document what works and what doesn't — this analysis informs RAG or fine-tuning decisions.
If prompt engineering proves insufficient, prototype RAG first unless latency requirements are strict. RAG systems are easier to iterate and less expensive to abandon if requirements change.
Consider fine-tuning only when you have clear evidence that RAG cannot meet your consistency, latency, or reasoning requirements. The investment is significant, but justified when the use case demands it.
The choice between RAG and fine-tuning isn't permanent. Many successful AI implementations start with one approach and evolve as requirements clarify and team expertise develops.
Need help determining the right AI approach for your organisation? Our AI engineering team has implemented both RAG and fine-tuning solutions across Australian mid-market companies. Start a conversation about your AI requirements.
Sarah Mitchell
Principal AI Engineer at Horizon Labs. Specialises in production LLM systems — RAG architectures, fine-tuning pipelines, and the evaluation harnesses that prove a model still works six months after launch. Eight years in machine learning, the last four shipping AI into Australian financial services and healthcare. PhD-level depth, founder-level pragmatism.


