AI Agents That Work: Architecture Patterns for Multi-Agent Systems
Multi-agent AI systems are becoming production reality for Australian enterprises, but most implementations fail due to poor architecture choices. Learn the orchestration patterns, communication protocols, and error handling strategies that separate proof-of-concept demos from production-ready systems.
Building AI Agents That Work: Architecture Patterns for Multi-Agent Systems
Multi-agent AI systems are becoming production reality for Australian enterprises, but most implementations fail due to poor architecture choices. The difference between a proof-of-concept demo and a system that handles real business processes lies in how you design agent communication, orchestration, and error handling from day one.
What Makes AI Agent Architecture Different?
AI agent architecture differs fundamentally from traditional microservices because agents make autonomous decisions, communicate asynchronously, and must handle uncertainty. Unlike REST APIs that return predictable responses, agents can fail unpredictably, misinterpret context, or produce outputs that require human validation.
Successful multi-agent systems require three core architectural decisions: how agents communicate, how they coordinate actions, and how they recover from failures. Get these wrong, and your system becomes an unreliable black box that engineering teams cannot debug or maintain.
Core Orchestration Patterns
Centralized Orchestrator Pattern
The centralized orchestrator pattern uses a single coordinator agent to manage task distribution and workflow execution. This orchestrator receives business requests, breaks them into subtasks, delegates to specialist agents, and assembles final responses.
class WorkflowOrchestrator:
def __init__(self, agents: Dict[str, Agent]):
self.agents = agents
self.task_queue = asyncio.Queue()
self.results_store = {}
async def execute_workflow(self, request: WorkflowRequest):
plan = await self.create_execution_plan(request)
for step in plan.steps:
agent = self.agents[step.agent_type]
result = await agent.execute(step.task, step.context)
if not self.validate_result(result, step.requirements):
return await self.handle_failure(step, result)
self.results_store[step.id] = result
return self.assemble_response(plan, self.results_store)
This pattern works well for linear workflows with clear dependencies, like document processing pipelines or customer service routing. However, it creates a single point of failure and bottleneck. The orchestrator must understand every agent's capabilities and failure modes.
Distributed Coordination Pattern
Distributed coordination allows agents to communicate directly and self-organize around tasks. Each agent maintains awareness of other agents' capabilities and current workload, negotiating task distribution through message passing.
class DistributedAgent:
def __init__(self, capabilities: List[str], message_bus: MessageBus):
self.capabilities = capabilities
self.message_bus = message_bus
self.active_tasks = set()
async def handle_task_request(self, task: Task):
if not self.can_handle(task):
await self.broadcast_task_request(task)
return
if self.is_overloaded():
await self.negotiate_load_sharing(task)
return
result = await self.execute_task(task)
await self.publish_result(result)
Distributed coordination scales better and eliminates single points of failure, but requires sophisticated consensus mechanisms and makes debugging significantly harder. Use this pattern for systems with dynamic agent populations or unpredictable workloads.
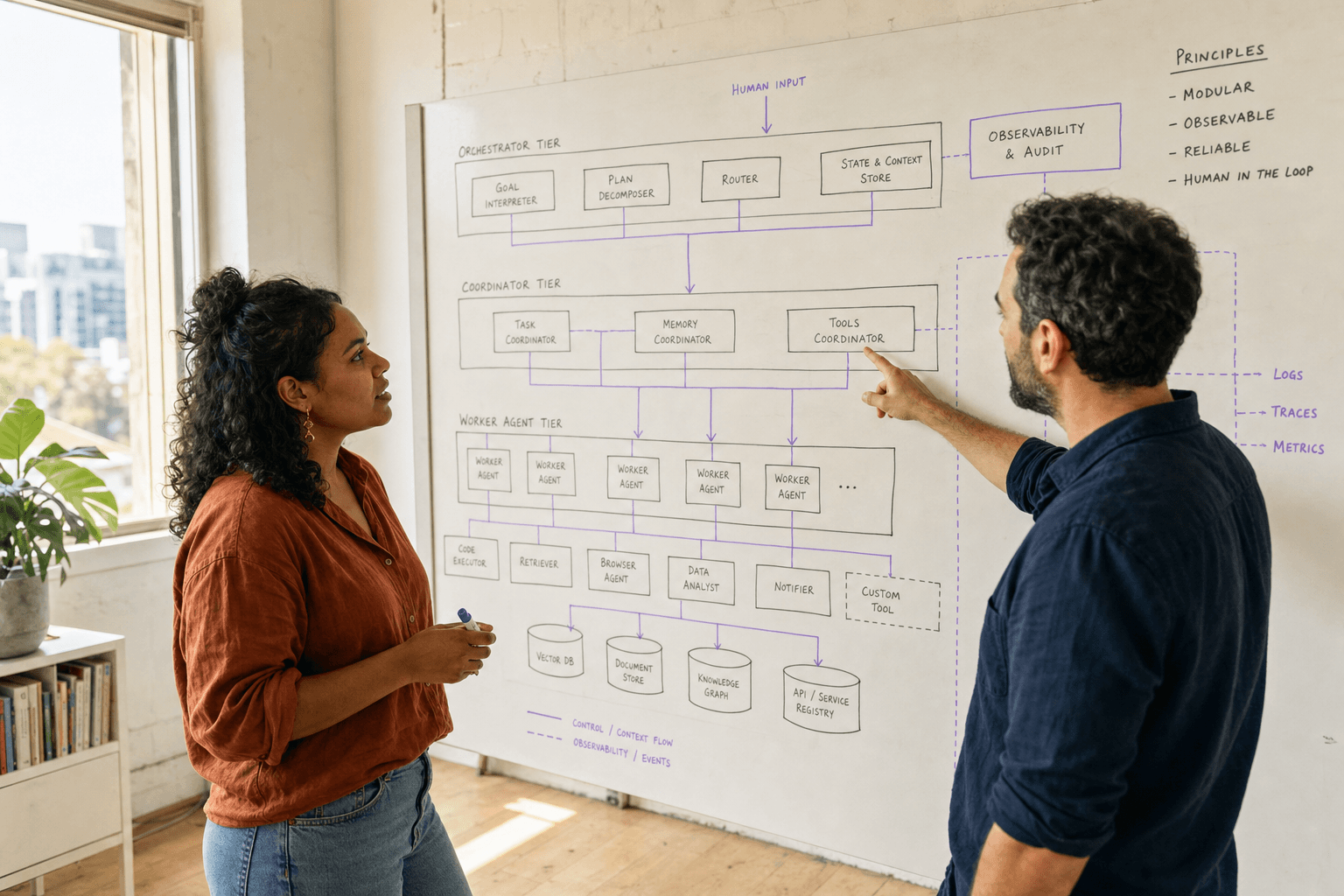
Hierarchical Agent Organization
Hierarchical organization combines centralized control with distributed execution. High-level coordinator agents manage strategy and resource allocation, while leaf agents handle specific tasks. This mirrors traditional organizational structures and maps well to business processes.
Manager agents track team performance, handle escalations, and coordinate with peer managers. Worker agents focus on specific domains but can request support or resources through their manager.
Agent Communication Protocols
Message-Based Communication
Message-based communication uses structured messages passed through queues or event streams. This provides loose coupling and natural failure boundaries, but requires careful schema design to prevent communication breakdowns.
Effective agent messages include:
- Message type and version: Enables protocol evolution
- Sender and recipient identification: Supports routing and debugging
- Correlation IDs: Links related messages across workflows
- Timeout and retry parameters: Defines failure handling behavior
- Structured payload: Includes typed data and metadata
{
"message_type": "task_request",
"version": "1.2",
"sender_id": "orchestrator-001",
"recipient_id": "analysis-agent-003",
"correlation_id": "workflow-abc123",
"timeout_ms": 30000,
"max_retries": 3,
"payload": {
"task_type": "document_analysis",
"document_url": "s3://bucket/doc.pdf",
"analysis_requirements": ["entities", "sentiment", "topics"],
"confidence_threshold": 0.8
}
}
Shared Memory Communication
Shared memory communication uses databases, caches, or object stores for agent coordination. Agents read and write to shared state, using locks or optimistic concurrency to prevent conflicts.
This pattern works well for agents that need access to large datasets or complex state, but creates coupling through shared schemas. Changes to data structures require coordinated agent updates.
Event Streaming
Event streaming uses append-only logs to broadcast agent actions and state changes. Other agents subscribe to relevant event streams, maintaining their own views of system state.
Event streaming provides natural audit trails and enables time-travel debugging, but requires careful stream partitioning and consumer management to prevent message ordering issues.
Tool Use and External Integration
Function Calling Architecture
Modern AI agents interact with external systems through structured function calls. The agent's language model generates function calls with typed parameters, which the runtime validates and executes.
class ToolRegistry:
def __init__(self):
self.tools = {}
def register_tool(self, func, schema: Dict):
self.tools[func.__name__] = {
'function': func,
'schema': schema,
'rate_limits': schema.get('rate_limits', {}),
'retry_policy': schema.get('retry_policy', DEFAULT_RETRY)
}
async def execute_tool_call(self, name: str, params: Dict):
if name not in self.tools:
raise ToolNotFoundError(f"Unknown tool: {name}")
tool = self.tools[name]
# Validate parameters against schema
if not self.validate_params(params, tool['schema']):
raise InvalidParametersError()
# Apply rate limiting
await self.check_rate_limits(name, tool['rate_limits'])
# Execute with retry logic
return await self.execute_with_retry(
tool['function'],
params,
tool['retry_policy']
)
Tool registries should include rate limiting, parameter validation, and automatic retry logic. External APIs fail unpredictably, so agents need robust error handling for tool calls.
API Gateway Pattern
For production systems, route all external tool calls through an API gateway that handles authentication, rate limiting, monitoring, and caching. This prevents agents from overwhelming external services and provides a single point for access control.
The gateway can also provide tool call logging for compliance and debugging. In regulated industries like Australian financial services, this audit trail is often mandatory.
Error Handling and Recovery
Circuit Breaker Implementation
Circuit breakers prevent cascading failures when downstream agents or services become unavailable. When error rates exceed thresholds, the circuit breaker opens, failing fast instead of waiting for timeouts.
class AgentCircuitBreaker:
def __init__(self, failure_threshold: int = 5, timeout_seconds: int = 60):
self.failure_threshold = failure_threshold
self.timeout_seconds = timeout_seconds
self.failure_count = 0
self.last_failure_time = None
self.state = 'CLOSED' # CLOSED, OPEN, HALF_OPEN
async def call_agent(self, agent: Agent, task: Task):
if self.state == 'OPEN':
if self._should_attempt_reset():
self.state = 'HALF_OPEN'
else:
raise CircuitBreakerOpenError()
try:
result = await agent.execute(task)
self._on_success()
return result
except Exception as e:
self._on_failure()
raise
Circuit breakers should be configured per agent type and task complexity. Short-running agents may need aggressive timeouts, while complex analysis agents need longer failure windows.
Compensating Transactions
When multi-agent workflows partially fail, compensating transactions undo completed work to maintain system consistency. Each agent should provide rollback operations for its actions.
For example, if an order processing workflow fails after charging a customer but before shipping, the compensation workflow refunds the charge and notifies the customer.
Dead Letter Queues
Messages that cannot be processed after maximum retries should move to dead letter queues for manual investigation. Include enough context in dead letter messages for engineers to reproduce and fix the underlying issues.
Human-in-the-Loop Checkpoints
Approval Workflows
Critical business decisions should require human approval before execution. Design approval workflows that pause agent execution, present context to human operators, and resume based on approval responses.
class ApprovalCheckpoint:
def __init__(self, approval_service: ApprovalService):
self.approval_service = approval_service
async def request_approval(self, decision: AgentDecision):
approval_request = {
'decision_type': decision.type,
'context': decision.context,
'confidence': decision.confidence,
'estimated_impact': decision.impact,
'agent_reasoning': decision.explanation
}
approval = await self.approval_service.request(
approval_request,
timeout=timedelta(hours=24)
)
if approval.status == 'REJECTED':
await decision.mark_rejected(approval.reason)
return False
return approval.status == 'APPROVED'
Approval workflows need timeout handling and escalation paths. If approvers don't respond within SLA, either auto-approve low-risk decisions or escalate to senior staff.
Confidence Thresholds
Agents should provide confidence scores for their outputs. Establish thresholds where low-confidence results trigger human review instead of automatic execution.
Thresholds should vary by use case impact. Financial transactions need higher confidence than content recommendations. Monitor threshold effectiveness and adjust based on false positive/negative rates.
Production Monitoring and Observability
Agent Performance Metrics
Monitor agent performance across multiple dimensions:
| Metric Category | Key Measurements | Alert Thresholds |
|---|---|---|
| Task Success | Completion rate, error rate by type | >5% error rate |
| Response Time | P50, P95, P99 latencies | P95 >30s |
| Resource Usage | CPU, memory, token consumption | >80% sustained |
| Communication | Message throughput, queue depth | Queue depth >100 |
| Tool Calls | External API success rate, timeouts | <95% success |
Distributed Tracing
Implement distributed tracing to track requests across multiple agents. Each message should carry trace context, allowing you to visualize complete workflow execution and identify bottlenecks.
Trace spans should include agent decisions, confidence scores, and tool call parameters. This data is essential for debugging failed workflows and optimizing agent performance.
Anomaly Detection
Use statistical methods to detect unusual agent behavior patterns. Sudden changes in task completion times, error rates, or output characteristics often indicate model degradation or external service issues.
Set up automated alerts for performance anomalies, but include enough context for on-call engineers to diagnose root causes quickly.
Evaluation and Testing Strategies
End-to-End Workflow Testing
Test complete multi-agent workflows, not just individual agents. Workflow integration bugs are common and difficult to catch with unit tests alone.
Create test scenarios that cover:
- Happy path execution with expected inputs
- Error conditions and recovery behavior
- Edge cases with unusual but valid inputs
- Load testing with realistic message volumes
- Chaos testing with random agent failures
Agent Behavior Verification
Verify that agents make decisions consistent with business requirements. Use evaluation datasets with known correct answers to measure agent accuracy over time.
For subjective tasks like content generation or customer service, use human evaluators to score agent outputs on relevant criteria like accuracy, helpfulness, and tone.
A/B Testing for Agent Performance
Run A/B tests comparing different agent configurations, orchestration patterns, or decision thresholds. Measure business metrics like task completion time, customer satisfaction, or cost per transaction.
A/B testing is especially valuable for tuning confidence thresholds and approval workflows. Small changes in thresholds can significantly impact both automation rates and error rates.
Successful multi-agent systems require careful AI engineering to handle the complex orchestration patterns and communication protocols discussed above. Many organisations also benefit from CTO advisory services when architecting these systems, as the technical decisions made early in development significantly impact long-term scalability and maintenance costs.
Getting Started: Architecture Decision Framework
When designing multi-agent systems, evaluate these architectural choices systematically:
- Coordination pattern: Start with centralized orchestration for predictable workflows, move to distributed coordination as complexity grows
- Communication method: Use message queues for loose coupling, shared memory for data-heavy agents, events for audit requirements
- Error handling: Implement circuit breakers and dead letter queues from day one
- Human oversight: Define approval workflows for high-impact decisions before going to production
- Monitoring strategy: Plan observability architecture alongside agent design
Most importantly, start simple and evolve architecture based on production requirements. The most elegant multi-agent system is worthless if it cannot handle real business processes reliably.
Building production-ready AI agents requires treating them as distributed systems first, AI systems second. Focus on reliability, observability, and maintainability. The AI capabilities are useless if your engineering team cannot debug failures or predict system behavior.
Need help designing AI agent architecture for your specific use case? Start a conversation with our AI engineering team. We've built multi-agent systems for Australian enterprises across logistics, financial services, and manufacturing.
Sarah Mitchell
Principal AI Engineer at Horizon Labs. Specialises in production LLM systems — RAG architectures, fine-tuning pipelines, and the evaluation harnesses that prove a model still works six months after launch. Eight years in machine learning, the last four shipping AI into Australian financial services and healthcare. PhD-level depth, founder-level pragmatism.


